AI has been on a phenomenal rise. Artificial neural network (ANN) accelerators can be extremely performant in executing the multiply accumulate (MAC) operations needed to compute AI. However, keeping them maximally utilised requires rapidly shuttling large amounts of model data between the memory and processing units.
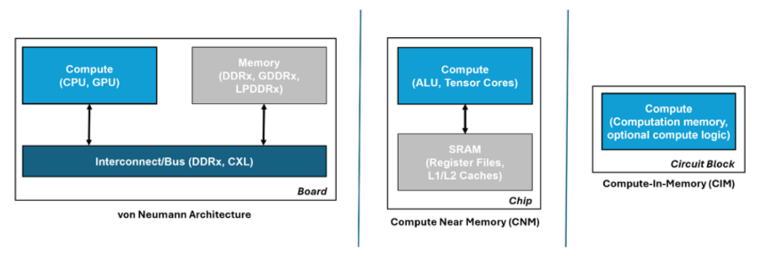
This becomes problematic in von Neumann architectures such as those used in ANN accelerators and modern computing in general where memory and processing are physically separated, and can quickly become a bottleneck that not only affects performance but also results in high energy consumption. In fact, data transfer is becoming more energy-consuming than the ANN computation it supports.
Moving the memory as close to the compute as possible lessens this issue and is the approach often used in ANN accelerators, either by combining memory and compute on the same die, or minimising the distance via 3D hybrid packaging. Such an approach is also popular in vision processors for resource-constrained edge devices, Hailo and Syntiant being good examples.
However, whilst this improves ANN performance, it doesn’t alleviate the bottleneck completely. A better approach, and more in keeping with neuromorphic principles, is to avoid moving the data at all, by conducting the compute operations across a memory array – in-memory compute (IMC).
Source: https://gsitechnology.com/compute-in-memory-computational-devices/
Such an approach reduces data transfers to a minimum thereby consuming orders of magnitude less energy than von Neumann architectures, and by minimising the memory bottleneck it also helps to maximise processor utilisation. Moreover, because the IMC elements act inherently as storage, realtime sensor data can be fed into them for immediate ‘through-wire’ processing for realtime edge applications.
Digital IMC
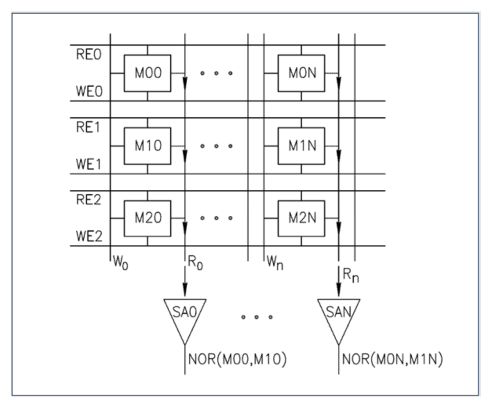
A common approach to IMC is to leverage existing mass production memory technologies such as SRAM and DRAM.
Instead of the usual practise of reading a single bit per memory row, if multiple simultaneous reads are carefully enacted it can provide a NOR function. This opens up the possibility of creating very fast Boolean logic twinned with low energy consumption using just the memory lines.
Source: https://gsitechnology.com/compute-in-memory-computational-devices/
Startups such as Synthara and UPMEM are already active in this space developing drop-in replacements for SRAM and DRAM memory chips respectively, and both only requiring minimal software updates to support them. Other startups include d-matrix and MemryX focusing on AI inference acceleration, and RAIN AI, an earlier stage startup yet to bring their solution to market but already targeting a hefty $150m round with support from Sam Altman.
Analog IMC
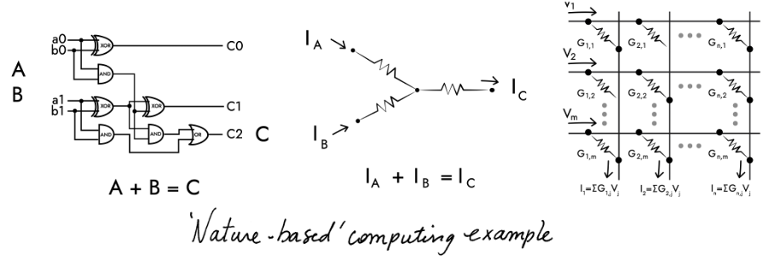
In-memory compute capabilities can also be achieved in the analog domain using a non-volatile memory array, and following a structure more closely aligned with the human brain, with each non-volatile memory element signifying a neuron and interconnections between elements forming a crossbar memory array to emulate the synapses.
Input voltages are applied along the rows of the crossbar array as shown in the diagram below. The output voltage of each neuron is multiplied by its conductance (representing the synapse weight) using Ohm’s Law, and the resulting current is summed up along each column using Kirchhoff’s Law to obtain the dot-product result, equivalent to the MAC operation mentioned earlier.
Source: https://www.aria.org.uk/wp-content/uploads/2023/11/ARIA-Unlocking-AI-compute-hardware-v1.0-1.pdf
Given that the non-volatile memory inherently maintains its state without requiring power, this approach is especially useful for AI inference in those situations where the model weights are seldom updated.
A variety of different implementation technologies are being explored by startups and other companies.
Mythic, for example, are using tuneable resistors (memristors) for the analog memory elements to target low-latency applications such as computer vision, whilst Semron have designed memcapacitive elements to avoid the intrinsic heating of memristive elements and thereby enable die stacking to support large ANNs (e.g., LLMs).
NIST and others have also explored the use of spintronics which exploits the intrinsic spin of electrons, in addition to their charge, to encode and process information. SpinEdge have developed an AI accelerator for edge devices using an array of non-volatile spintronic memory cells for storing the neural network weights.
And finally, IBM have explored the use of multi-level phase-change materials (PCMs) in their Hermes prototype chip. PCMs are particularly good for developing non-volatile memory, and with the added advantage of allowing single bits to be changed without erasing an entire block of cells, hence useful for updating individual model weights.
On the downside, given the analog nature of these different technologies, they suffer from variability across the memory elements which may require retraining of the network after it’s been loaded onto the chip.
Analog can also be limited in terms of precision, and whilst this can be improved by increasing the components’ dynamic range, noise limitations can require higher voltages, and hence higher energy consumption, thus negating the core strength of this approach versus the digital alternatives.
Another consideration is size; by putting all the weights in the crossbars, this can result in a larger chip size compared to the von Neumann approach of fetching the ANN weights as needed. It can also suffer from issues of reliability when scaling to larger systems, and poor area utilisation if the fixed memory array is larger than needed for a given ANN.
Some applications may also require interfacing with digital logic, hence requiring analog/digital conversion which will introduce latency, additional energy consumption, and potentially noise in the ADC/DAC process.
In summary, whilst analog approaches offer advantages in energy efficiency and being able to pre-load ANN models for edge deployment, they also present a number of challenges related to precision, integration, and design complexity that put them, for now, at a disadvantage to their digital equivalents.
Takeaways
As ANN models increase in size, and especially in the case of LLMs with billions of parameters, the energy and performance cost of shuttling data to and from the processing units within the classical von Neumann architecture will become an ever-increasing issue.
Storing the data closer to the processing units is one approach, with the memory elements and processing units ideally being brought together in novel architectures such as in-memory compute.
However, as noted in a previous article on neuromorphic computing, the tight integration of memory and compute might require the memory to be fabricated using the same expensive processes as the digital logic, and this can be 100x the cost of off-chip SRAM or DRAM used in conventional architectures.
And in the case of analog IMC, whilst these approaches show promise in dramatically reducing energy consumption, they also face a number of implementation challenges.
It’s therefore unlikely that in-memory compute solutions will outperform GPUs and ANN accelerators at large scale in data centres.
They are though much better suited to edge applications, such as computer vision, sensing, and robotics where their realtime capabilities are mission critical (Hailo, Syntiant), or in resource-constrained devices such as wearables (Synthara), or more generally for use across a range of edge AI applications in automotive, logistics and IoT (MemryX).
With the race to bring AI applications to the edge this is a vibrant space, and one that’s ripe for startup innovation.
Cutting-edge AI/ML models, and especially large language and multimodal models (LLMs; LMMs), are capable of a wide-range of sophisticated tasks, but their sheer size and computational complexity often precludes them from being run locally on devices such as laptops and smartphones.
Usage has therefore been dependent on submitting all queries and data to the cloud, which may be impractical in situations with poor connectivity, suboptimal in terms of latency, or simply undesirable in the case of sensitive personal or company confidential information.
Being able to deploy and run complex AI/ML models on resource-constrained edge devices would unlock opportunities across a swathe of areas including consumer (wearables, smartphones, health monitoring), automotive (computer vision), industrial (predictive maintenance, anomaly detection, AMRs), and space (Earth Observation) amongst others.
Realising these opportunities though is wholly dependent on reducing the computational complexity of the AI/ML models and/or achieving a step-change in compute and energy efficiency at the edge.
Compressing the model to reduce its size is a good first step, and in doing so reduces the memory footprint needed for accommodating the model and the amount of compute and energy needed to run it. Options for reducing model size include quantisation, pruning, and knowledge distillation.
Quantisation
The human brain can simultaneously compute, reason and store information, performing the equivalent of an exaflop whilst using a mere 20W of power. In part, this impressive energy efficiency comes through taking a more relaxed attitude to precision – the same can be applied to ML models.
Quantisation reduces the precision of model weights/activations from the standard 32-bit floating-point numbers (FP32) used when training the model to lower bit widths such as FP8 or INT8 for inference (8-bit integers being much simpler to implement in logic and requiring 10x less energy than FP32).
Doing so risks sacrificing accuracy, but the loss tends to be small (~1%), and can often by recovered through quantisation-aware fine-tuning of the model.
Compression techniques such as GPTQ have enabled AI models to be reduced further down to 3-4 bits per weight, and more recently researchers have managed to reduce model size to as little as 2 bits through the combined use of AQLM and PV-Tuning.
Such an approach though still relies on high precision during training.
An alternate approach is to define low-bitwidth number formats for use directly within AI training and inference. Earlier this year, AMD, Arm, Intel, Meta, Microsoft, NVIDIA, and Qualcomm formed the Microscaling Formats (MX) Alliance to do this with the goal of standardising 6- and 4-bit block floating point formats as drop-in replacements for AI training and inferencing with only a minor impact on accuracy.
Pruning
Another way of reducing model size is to remove redundant or less important weights and neurons, similar to how the brain prunes connections between neurons to emphasise important pathways. Such a technique can typically reduce model size by 20-50% and potentially more, although higher levels require careful fine-tuning after pruning to retain model performance. NVIDIA’s TensorRT, Intel’s OpenVINO, Google LiteRT and PyTorch Mobile all offer a range of tools for model pruning, quantisation and deployment to edge devices.
Knowledge distillation & SLMs
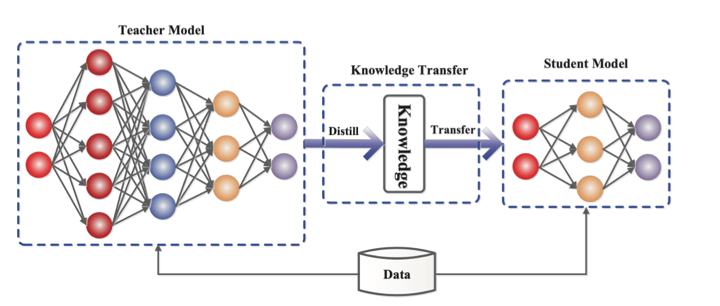
In situations where the required functionality can be clearly defined, such as in computer vision or realtime voice interfaces, it may be possible to employ a much smaller language model (SLM) that has been specifically trained for the task.
Such models can be developed either through a process of knowledge distillation, in which a smaller network is taught step by step using a bigger pre-rained network, or through training using a highly curated ‘textbook quality’ dataset.
Source: https://arxiv.org/abs/2006.05525
Microsoft’s Phi-3, for example, is a 3.8B parameter model that is 50x smaller than the flagship LLMs from OpenAI et al but with similar performance in the specific capabilities targeted. The forthcoming Copilot+ laptops will include a number of these SLMs, each capable of performing different functions to aid the user.
Apple have similarly adopted the SLM approach for the iPhone, but differ by combining a single pre-trained model with curated sets of LoRA weights that are loaded into the model on demand to adapt it to different tasks rather than needing separate models. By further shrinking the model using 3.5bits per parameter via quantisation, they’ve managed to squeeze the performance of an LLM into the recently launched iPhone 16 (A18 chip: 8GB, 16-core Neural Engine, 5-core GPU) to support their Apple Intelligenceproposition.
This is a vibrant and fast moving space, with research teams in the large AI players and academia continually exploring and redefining the art of the possible. As such, it’s a challenging environment for startups to enter with their own algorithmic innovations and successfully compete, although companies such as TitanML have developed a comprehensive inference stack employing Activation-aware Weight Quantization (AWQ), and Multiverse Computing have successfully demonstrated the use of Quantum-inspired tensor networks for accelerating AI and cutting compute costs.
Opportunities also exist in situations where a startup has privileged access to a sector-specific dataset and hence is able to generate fine-tuned AI solutions for addressing particular industry pain points at the edge – few have surfaced to-date, hence this remains a largely untapped opportunity for startups to explore with suitable strategic partners.
To fully democratise the use of AI/ML, and LLMs/LMMs in particular, will though also require a step change in compute performance and energy efficiency at the edge. Later articles will dive into the future of compute, and explore novel architectures including neuromorphic, in-memory, analog, and of course quantum computing, as well as a few others on the horizon.
