The future of AI compute is photonics… or is it?
Exploring the potential of photonics to improve efficiency in the future of compute
Cutting-edge AI/ML models, and especially large language and multimodal models (LLMs; LMMs), are capable of a wide-range of sophisticated tasks, but their sheer size and computational complexity often precludes them from being run locally on devices such as laptops and smartphones.
Usage has therefore been dependent on submitting all queries and data to the cloud, which may be impractical in situations with poor connectivity, suboptimal in terms of latency, or simply undesirable in the case of sensitive personal or company confidential information.
Being able to deploy and run complex AI/ML models on resource-constrained edge devices would unlock opportunities across a swathe of areas including consumer (wearables, smartphones, health monitoring), automotive (computer vision), industrial (predictive maintenance, anomaly detection, AMRs), and space (Earth Observation) amongst others.
Realising these opportunities though is wholly dependent on reducing the computational complexity of the AI/ML models and/or achieving a step-change in compute and energy efficiency at the edge.
Compressing the model to reduce its size is a good first step, and in doing so reduces the memory footprint needed for accommodating the model and the amount of compute and energy needed to run it. Options for reducing model size include quantisation, pruning, and knowledge distillation.
Quantisation
The human brain can simultaneously compute, reason and store information, performing the equivalent of an exaflop whilst using a mere 20W of power. In part, this impressive energy efficiency comes through taking a more relaxed attitude to precision – the same can be applied to ML models.
Quantisation reduces the precision of model weights/activations from the standard 32-bit floating-point numbers (FP32) used when training the model to lower bit widths such as FP8 or INT8 for inference (8-bit integers being much simpler to implement in logic and requiring 10x less energy than FP32).
Doing so risks sacrificing accuracy, but the loss tends to be small (~1%), and can often by recovered through quantisation-aware fine-tuning of the model.
Compression techniques such as GPTQ have enabled AI models to be reduced further down to 3-4 bits per weight, and more recently researchers have managed to reduce model size to as little as 2 bits through the combined use of AQLM and PV-Tuning.
Such an approach though still relies on high precision during training.
An alternate approach is to define low-bitwidth number formats for use directly within AI training and inference. Earlier this year, AMD, Arm, Intel, Meta, Microsoft, NVIDIA, and Qualcomm formed the Microscaling Formats (MX) Alliance to do this with the goal of standardising 6- and 4-bit block floating point formats as drop-in replacements for AI training and inferencing with only a minor impact on accuracy.
Pruning
Another way of reducing model size is to remove redundant or less important weights and neurons, similar to how the brain prunes connections between neurons to emphasise important pathways. Such a technique can typically reduce model size by 20-50% and potentially more, although higher levels require careful fine-tuning after pruning to retain model performance. NVIDIA’s TensorRT, Intel’s OpenVINO, Google LiteRT and PyTorch Mobile all offer a range of tools for model pruning, quantisation and deployment to edge devices.
Knowledge distillation & SLMs
In situations where the required functionality can be clearly defined, such as in computer vision or realtime voice interfaces, it may be possible to employ a much smaller language model (SLM) that has been specifically trained for the task.
Such models can be developed either through a process of knowledge distillation, in which a smaller network is taught step by step using a bigger pre-rained network, or through training using a highly curated ‘textbook quality’ dataset.
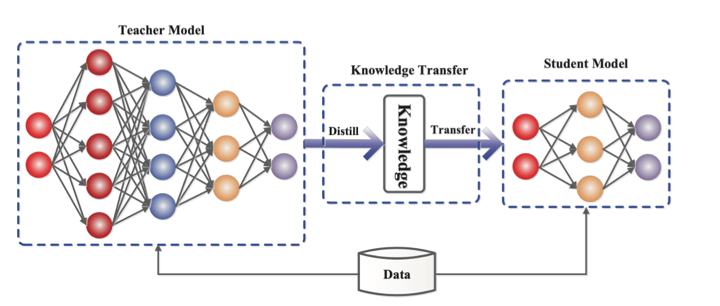
Source: https://arxiv.org/abs/2006.05525
Microsoft’s Phi-3, for example, is a 3.8B parameter model that is 50x smaller than the flagship LLMs from OpenAI et al but with similar performance in the specific capabilities targeted. The forthcoming Copilot+ laptops will include a number of these SLMs, each capable of performing different functions to aid the user.
Apple have similarly adopted the SLM approach for the iPhone, but differ by combining a single pre-trained model with curated sets of LoRA weights that are loaded into the model on demand to adapt it to different tasks rather than needing separate models. By further shrinking the model using 3.5bits per parameter via quantisation, they’ve managed to squeeze the performance of an LLM into the recently launched iPhone 16 (A18 chip: 8GB, 16-core Neural Engine, 5-core GPU) to support their Apple Intelligenceproposition.
This is a vibrant and fast moving space, with research teams in the large AI players and academia continually exploring and redefining the art of the possible. As such, it’s a challenging environment for startups to enter with their own algorithmic innovations and successfully compete, although companies such as TitanML have developed a comprehensive inference stack employing Activation-aware Weight Quantization (AWQ), and Multiverse Computing have successfully demonstrated the use of Quantum-inspired tensor networks for accelerating AI and cutting compute costs.
Opportunities also exist in situations where a startup has privileged access to a sector-specific dataset and hence is able to generate fine-tuned AI solutions for addressing particular industry pain points at the edge – few have surfaced to-date, hence this remains a largely untapped opportunity for startups to explore with suitable strategic partners.
To fully democratise the use of AI/ML, and LLMs/LMMs in particular, will though also require a step change in compute performance and energy efficiency at the edge. Later articles will dive into the future of compute, and explore novel architectures including neuromorphic, in-memory, analog, and of course quantum computing, as well as a few others on the horizon.

Exploring the potential of photonics to improve efficiency in the future of compute

Exploring more esoteric approaches to the future of compute
