Introduction
The global economy is fuelled by knowledge and information, the digital sector growing 6x faster than the economy as a whole. AI will act as a further accelerant in boosting the economy and has the potential of being transformative across many sectors.

Figure 1: GenAI wide application
However, in realising this promise, GenAI faces a number of challenges: 1) foundational LLMs have a great set of skills and generalist knowledge, but know nothing about individual companies’ products & services; 2) whilst LLMs are great at providing an instant answer, they often misunderstand the question or simply hallucinate in their response; equally, 3) LLMs need to improve in their reasoning capabilities to understand and solve complex problems; and finally, 4) LLMs are compute intensive, inhibiting their widespread adoption.
This article looks at how these challenges are being addressed.
Tailoring LLMs: Fine-tuning
First and foremost, LLMs need customisation to understand company data & processes and best deliver on the task at hand. Pre-training, in which a company develops its own LLM trained on their data might seem like the obvious choice but is not easy, requiring massive amounts of data, expensive compute, and a dedicated team.
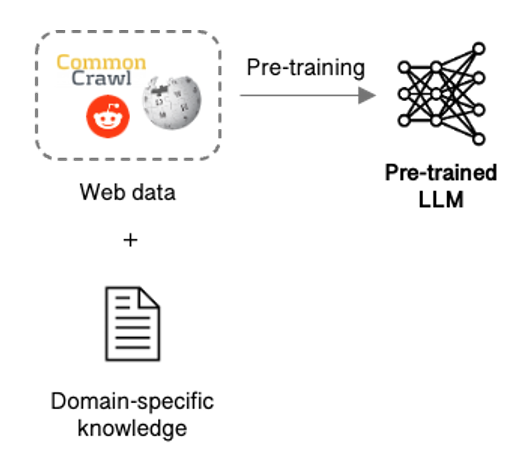
Figure 2: LLM pre-training
A simpler approach takes an existing foundational model and fine-tunes it by adapting its parameters to obtain the knowledge, skills and behaviour needed.
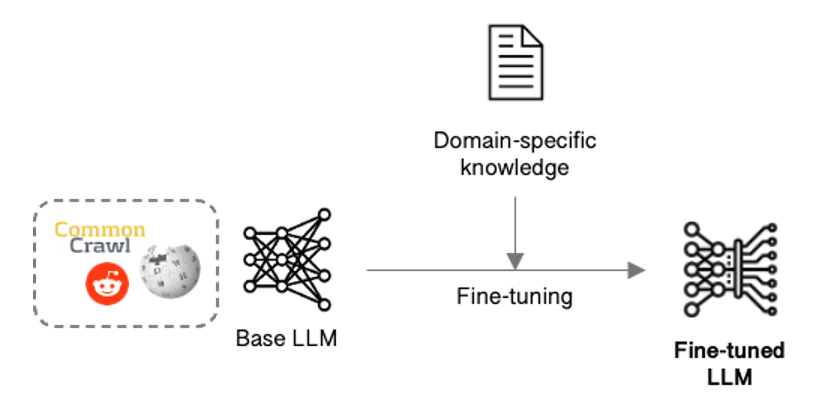
Figure 3: LLM fine-tuning
Fine-tuning though updates all the parameters, so can quickly become costly and slow if adapting a large LLM, and keeping it current will probably require re-tuning on a regular basis. Parameter-efficient fine-tuning (PEFT) techniques such as Low-rank Adaptation (LoRA) address this issue by targeting a subset of the parameters, speeding up the process and reducing cost.
Rather than fine-tuning the model, an alternate is to provide guidance within the prompt, an approach known as in-context learning.
In-context Learning
Typically, LLMs are prompted in a zero-shot manner:

Figure 4: Zero-shot prompting [source: https://www.oreilly.com]
LLMs do surprisingly well when prompted in this way, but perform much better if provided with more guidance via a few input/output examples:

Figure 5: Few-shot ICL [source: https://www.oreilly.com]
As is often the case with LLMs, more examples tends to improve performance, but not always – irrelevant material included in the prompt can drastically deteriorate the LLM’s performance. In addition, many LLMs pay most attention to the beginning and end of their context leaving everything else “lost in the middle”.
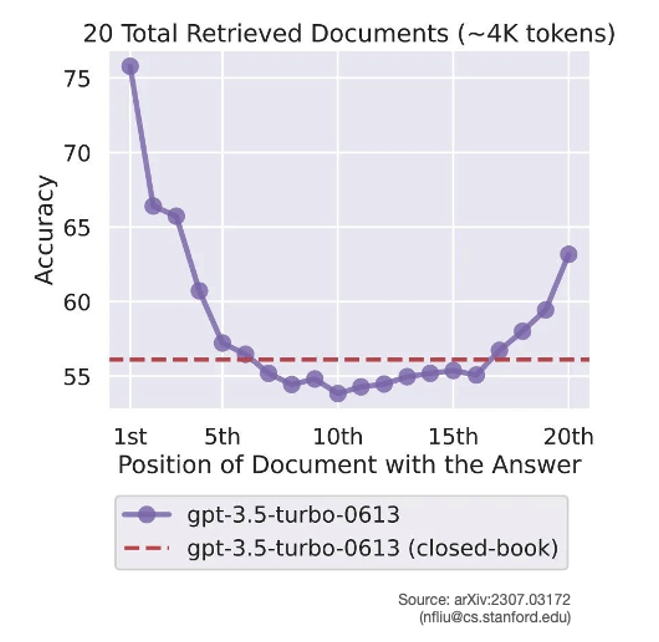
Figure 6: Accuracy doesn’t scale with ICL volume
In-context learning neatly side-steps the effort of fine-tuning but results in lengthier prompts which increases compute and cost; a few-shot PEFT approach may produce better results, and be cheaper in the long run.
Whilst fine-tuning and in-context learning hones the LLM’s skills to particular tasks, it doesn’t acquire new knowledge. For tasks such as answering customer queries on a company’s products and services, the LLM needs to be provided with supplementary knowledge at runtime. Retrieval-Augmented Generation (RAG) is one such mechanism for doing that.
Retrieval-Augmented Generation (RAG)
The RAG approach introduces a knowledge store from which relevant text chunks can be retrieved and appended to the prompt fed into the LLM. A keyword search would suffice, but it’s much better to retrieve information based on vector similarity via the use of embeddings:
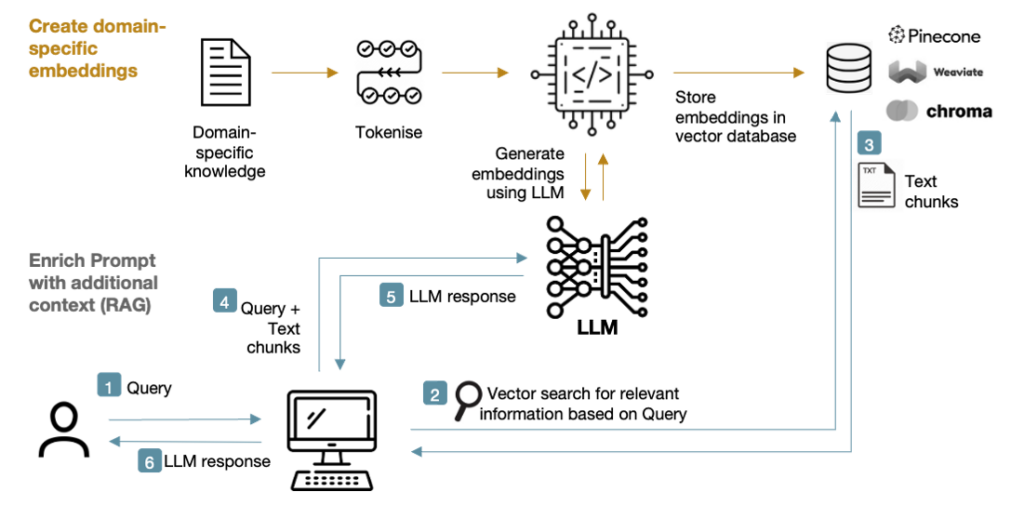
Figure 7: RAG system
RAG boosts the knowledge available to the LLM (hence reducing hallucinations), prevents the LLM’s knowledge becoming stale, and also gives access to the source for fact-checking.
RAPTOR goes one step further by summarising the retrieved text chunks at different abstraction levels to fit the target LLM’s maximum context length (or to fit within a given token budget), whilst Graph RAG uses a graph database to provide contextual information to the LLM on the retrieved text chunk thus enabling deeper insights.
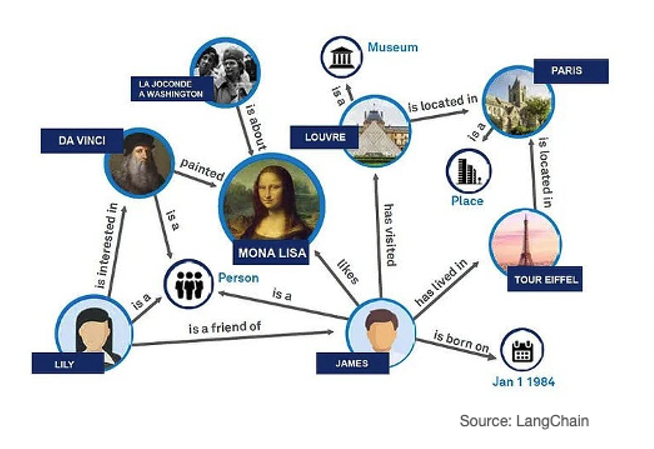
Figure 8: GraphRAG
Small Language Models (SLMs)
Foundational LLMs incorporate a broad set of skills but their sheer size precludes them from being run locally on devices such as laptops and phones. For singular tasks, such as being able to summarise a pdf, or proof-read an essay, a Small Language Model (SLM) that has been specially trained for the task will often suffice. Microsoft’s Phi-3, for example, has demonstrated impressive capabilities in a 3.8B parameter model small enough to fit on a smartphone. The recently announced Copilot+ PCs will include a number of these SLMs, each capable of performing different functions to aid the user.

Figure 9: Microsoft SLM Phi-3
Apple have also adopted the SLM approach to host LLMs on Macs and iPhones, but interestingly have combined the SLM with different sets of LoRA weights loaded on-demand to adapt it to different tasks rather than needing to deploy separate models. Combined with parameter quantisation, they’ve squeezed the performance of an LLM across a range of tasks into an iPhone 15 Pro whilst still generating an impressive 30 tokens/s output speed.
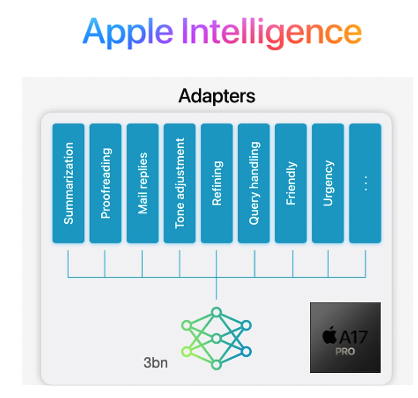
Figure 10: Apple Intelligence
Reasoning
Whilst LLMs are surprisingly good across a range of tasks, they still struggle with reasoning and navigating complex problems.
Using the cognitive model devised by the late Daniel Kahneman, LLMs today arguably resemble the Fast-Thinking system, and especially so in zero-shot mode, trying to produce an instant response, and often getting it wrong. For AI to be truly intelligent, it needs to improve its Slow Thinking and reasoning capabilities.

Figure 11: Daniel Kahneman’s cognitive system model
Instruction Prompting
Experimentation has found, rather surprisingly, that including simple instructions in the prompt can encourage the LLM to take a more measured approach in producing its answer.
Chain of Thought (CoT) is one such technique in which the model is instructed with a phrase such as “Let’s consider step by step…” to encourage it to break down the task into steps, whilst adding a simple “be concise” instruction can shorten responses by 50% with minimal impact on accuracy. Tree of Thoughts (ToT) is a similar technique, but goes further by allowing multiple reasoning paths to be explored in turn before settling on a final answer.
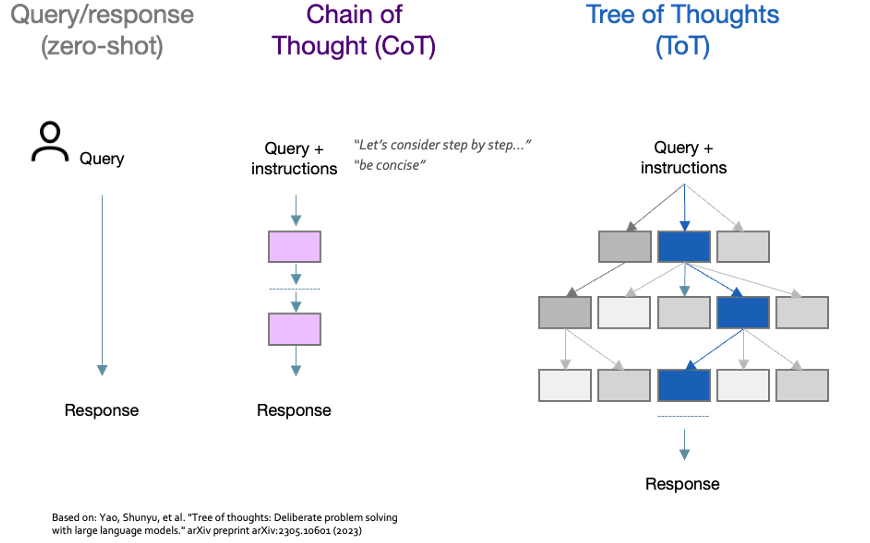
Figure 12: CoT and ToT instruction prompting
Self-ask goes further still by asking the model to break down the input query into sub-questions and answer each of these first (and with the option of retrieving up-to-date information from external sources), before using this knowledge to compile the final answer – essentially a combination of CoT and RAG.
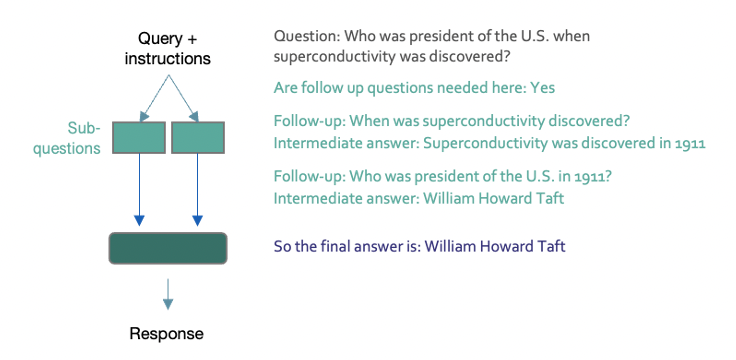
Figure 13: Self-ask instruction prompting
Agentic Systems
Agentic systems combine the various planning & knowledge-retrieval techniques outlined so far with additional capabilities for handling more complex tasks. Most importantly, agentic systems examine their own work and identify ways to improve it, rather than simply generating output in a single pass. This self-reflection is further enhanced by giving the AI Agent tools to evaluate its output, such as running the code through unit tests to check for correctness, style, and efficiency, and then refining accordingly.
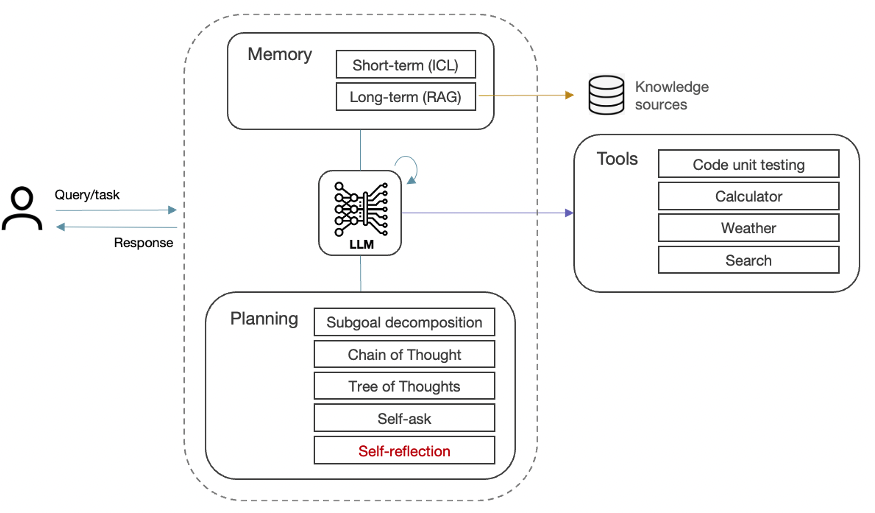
Figure 14: Agentic system
More sophisticated agentic workflows might separate the data gathering, reasoning and action taking components across multiple agents that act autonomously and work collaboratively to complete the task. Some tasks might even be farmed out to multiple agents to see which comes back with the best outcome; a process known as response diversity.
Compared to the usual zero shot approach, agentic workflows have demonstrated significant increases in performance – an agentic workflow using the older GPT-3.5 model (or perhaps one of the SLMs mentioned earlier) can outperform a much larger and sophisticated model such as GPT-4.
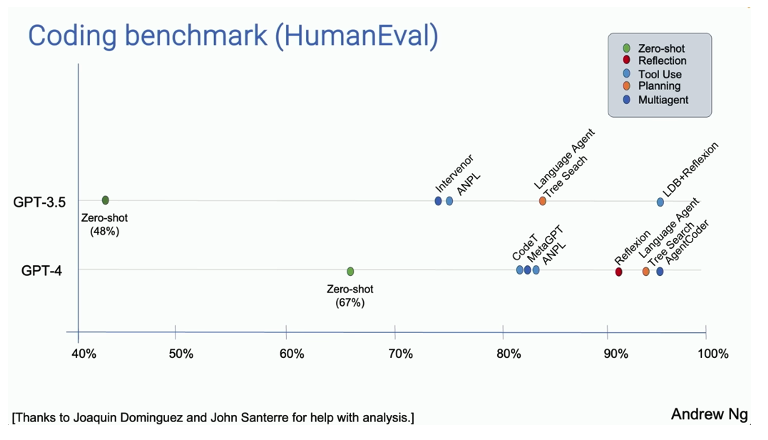
Figure 15: Agentic system performance
It’s still early days though, and there remain a number of areas that need further optimisation. LLM context length, for instance, can place limits on the amount of historical information, detailed instructions, input from other agents, and own self-reflection that can be accommodated in the reasoning process. Separately, the iterative nature of agentic workflows can result in cascading errors, hence requiring intermediate quality control steps to monitor and rectify errors as they happen.
Takeaways
LLMs burst onto the scene in 2022 with impressive fast-thinking capabilities albeit plagued with hallucinations and knowledge constraints. Hallucinations remain an area not fully solved, but progress in other areas has been rapid: expanding the capabilities with multi-modality, addressing the knowledge constraints with RAG, and integrating LLMs at an application and device level via CoPilot, CoPilot+ PCs & Apple Intelligence using SLMs and LoRA.
2024 will likely see agentic workflows driving massive progress in automation, and LLMs gradually improving their capabilities in slow-thinking for complex problem solving.
And after that? Who knows, but as the futurologist Roy Amara sagely pointed out, “We tend to overestimate the effect of a technology in the short run and underestimate the effect in the long run”… so let’s see.
The popularity of ChatGPT has introduced the world to large language models (LLMs) and their extraordinary abilities in performing natural language tasks.
According to Accenture, such tasks account for 62% of office workers’ time, and 65% of that could be made more productive through using LLMs to automate or augment Enterprise working practises thereby boosting productivity, innovation, and customer engagement.
To give some examples, LLMs could be integrated into Customer Services to handle product queries, thereby improving response times and customer satisfaction. Equally, LLMs could assist in drafting articles, scripts, or promotional materials, or be used by analysts for summarising vast amounts of information, or gauging market sentiment by analysing customer reviews and feedback.
Whilst potentially disruptive and likely to lead to some job losses (by the mid-2030s, up to 30% of jobs could be automated), this disruption and new way of working is also forecast to grow global revenues by 9%.
It’s perhaps not surprising then that Enterprise executives are showing a keen interest in LLMs and the role they could play in their organisations’ strategies over the next 3 to 5 years.
Large language models such as OpenAI’s GPT-4 or GPT-3.5 (upon which ChatGPT is based) or open source alternatives such as Meta’s recently launched Llama2, are what’s known as foundation models.
Such models are pre-trained on a massive amount of textual data and then tuned through a process of alignment to be performant across a broad range of natural language tasks. Crucially though, their knowledge is limited by the extent of the data they were trained on, and their behaviour is dictated by the approach and objectives employed during the alignment phase.
To put it bluntly, a foundational LLM, whilst exhibiting a dazzling array of natural language skills, is less adept at generating legal documents or summarising medical information, and may be inadequate for those Customer Support applications requiring more empathy, and will certainly lack detailed knowledge on a particular product or business.
To be truly useful therefore, LLMs need to be adapted to the domain and particular use cases where they’ll be employed.
Domain-specific pre-training
One approach would be to collect domain-specific data and train a new model.
However, pre-training your own LLM from scratch is not easy, requiring massive amounts of data, lots of expensive compute hours for training the model, and a dedicated team working on it for weeks or even months. As a result, very few organisations choose this path, although notable examples include BloombergGPT (finance) and Med-PaLM 2 (medicine) and Nvidia have recently launched the NeMo framework to lend a helping hand.
Nonetheless, training a dedicated model is a serious undertaking and only open to those with the necessary resources. For everyone else, an alternate (and arguably easier) approach is to start with an existing foundational model such as GPT-3.5 and fine-tune from there.
Fine-tuning
As a form of transfer learning, fine-tuning adapts the parameters within a foundational model to better perform particular tasks.
Guidance from OpenAI for gpt-3.5-turbo indicates that 50-100 well-crafted examples is usually sufficient to fine-tune a model, although the amount will ultimately depend on the use case.
In comparison to domain-specific pre-trained models which require lots of resource, fine-tuning a foundational model requires less data, costs less, and can be completed in days, putting it well within the reach of many companies.
But it’s not without its drawbacks…
A common misconception is that fine-tuning enables the model to acquire new information, but in reality it only teaches it to perform better within particular tasks, a goal which can also be achieved through careful prompting as we’ll see later.
Fine-tuning also won’t prevent hallucinations that undermine the reliability and trustworthiness of the model’s output; and there is always a risk of introducing biases or inaccuracies into the model via the examples chosen, or inadvertently training it with sensitive information which subsequently leaks out (hence consideration should be given to using synthetic data).
Where support is required for a diverse set of tasks or edge cases within a given domain, relying on fine-tuning alone might result in a model that is too generic, performing poorly against each subtask. In such a situation, individual models may need to be created for each task and updated frequently to stay current and relevant as new knowledge becomes available, hence becoming a resource-intensive and cumbersome endeavour.
Fortunately, there are other techniques that can be employed, either in concert with or replacing fine-tuning entirely – prompt engineering.
Few-shot prompting
Irrespective of how a language model has been pre-trained and whether or not it’s been fine-tuned, the usefulness of its output is directly related to the quality of the prompt it receives. As so aptly put by OpenAI, “GPTs can’t read your mind“.
Although models can perform relatively well when prompted in a zero-shot manner (i.e., comprising just the task description and any input data), they can also be inconsistent, and may try to answer a question by regurgitating random facts or making something up from their training data (i.e., hallucinating) – they might know how words relate statistically, but they don’t know what they mean.
Output can be improved by supplementing the prompt with one or more input/output examples (few-shot) that provide context to the instruction as well as guidance on desired format, style of response and length; this is known as in-context learning (ICL); see below:

The order in which examples are provided can impact a model’s performance, as can the format used. Diversity is also incredibly important, models prompted with a diverse set of examples tending to perform better (although only the larger foundational models such as GPT-4 cope well with examples that diverge too far from what the model was originally pre-trained with).
Retrieval Augmented Generation
A good way of achieving this diversity is to retrieve task-specific examples from domain-specific knowledge sources using frameworks such as LlamaIndex, LangChain, HoneyHive, Lamini or Microsoft’s LLM-AUGMENTER.
Commonly referred to as Retrieval Augmented Generation, this approach ensures that the model has access to the most current and reliable domain-specific facts (rather than the static corpus it was pre-trained with), and users have visibility of the model’s sources thereby enabling its responses to be checked for accuracy.
As so aptly put by IBM Research, “It’s the difference between an open-book and a closed-book exam“, and hence it’s not surprising that LLMs perform much better when provided with external information sources to draw upon.
A straightforward way of implementing the RAG method is via a keyword search to retrieve relevant text chunks from external documentation, but a better approach is to use embeddings.
Put simply, embedding is a process by which the text is tokenised and passed through the LLM to create a numerical representation of the semantic meaning of the words and phrases within the text, and this representation is then be stored in a vector database (such as Pinecone, Weaviate or Chroma).
Upon receiving a query, the RAG system conducts a vector search of the database based on an embedding of the user query, retrieves relevant text chunks based on similarity and appends them to the prompt for feeding into the LLM:

Care though is needed to not overload the prompt with too much information as any increase in the prompt size directly increases the compute, time and cost for the LLM to derive an output (computation increasing quadratically with input length), and also risks exceeding the foundation model’s max prompt window size (and especially so in the case of open source models which typically have much smaller windows).
Whilst providing additional context and task-specific data should reduce the instances of hallucinations, LLMs still struggle with complex arithmetic, common sense, or symbolic reasoning, hence attention is also needed to the way the LLM is instructed to perform the task, an approach known as instruction prompting.
Instruction prompting
Chain of Thought (CoT) is one such technique, explored by Google and OpenAI amongst others, in which the model is directly instructed to follow smaller, intermediate steps towards deriving the final answer. Extending the prompt instruction with a phrase as simple as “Let’s consider step by step…” can have a surprising effect in helping the model to break down the task into steps rather than jumping in with a quick, and often incorrect, answer.
Self-ask is a similar approach in which the model is asked to generate and then answer sub-questions about the input query first (and with the option of farming out these sub-questions to Google Search to retrieve up-to-date answers), before then using this knowledge to compile the final answer (essentially a combination of CoT and RAG).
Yet another technique, Tree of Thoughts (ToT) is similar in generating a solution based on a sequence of individual thoughts, but goes further by allowing multiple reasoning paths to be considered simultaneously (forming a tree of potential thoughts) and exploring each in turn before settling on a final answer.

Whilst proven to be effective, these various instruction prompting techniques take a linear approach that progresses from one thought to the next. Humans think a little differently, following and sometimes combining insights from different chains of thought to arrive at the final answer. This reasoning process can be modelled as a graph structure and forms yet another area of research.
A final technique, which might seem even more peculiar than asking the model to take a stepwise approach (CoT and ToT) is to assign it a “role” or persona within the prompt such as “You are a famous and brilliant mathematician”. Whilst this role based prompting may seem bizarre, it’s actually providing the model with additional context to better understand the question, and has been found surprisingly to produce better answers.
Options & considerations
The previous sections have identified a range of techniques that can be employed to contextualise an LLM to Enterprise tasks, but which should you choose?
The first step is to choose whether to generate your own domain pre-trained model, fine-tune an existing foundational model, or simply rely on prompting at runtime:

There’s more discussion later on around some of the criteria to consider when selecting which foundational model to use…
Fine-tuning may at first seem the most logical path, but requires a careful investment of time and effort, hence sticking with a foundational model and experimenting with the different prompting techniques is often the best place to start, a sentiment echoed by OpenAI in their guidance for GPT.
Choice of which techniques to try will be dependent on the nature of the task:

Good results can often be achieved by employing different prompting techniques in combination:
- Detailed instructions (instruction prompting) – especially where the task involves complex reasoning
- Carefully chosen set of examples (few-shot learning) – to demonstrate the tone, format and length of output that is required
- Supplementary information (in-context learning, RAG & embeddings) – retrieved from domain-specific knowledge sources to provide more context
It’s also about balance – few-shot learning typically consumes a lot of tokens which can be problematic given the limited window size of many LLMs. So rather than guiding the model in terms of desired behaviour via a long set of examples, this can be offset by incorporating a more precise, textual description of what’s required via instruction prompting.
Prompt window size can also be a limitation in domains such as medical and legal which are more likely to require large amounts of information to be provided in the prompt; for instance most research papers (~5-8k tokens) would exceed the window size of the base GPT-3.5 model as well as many of the open source LLMs which typically only support up to 2,000 tokens (~1,500 words).
Choosing a different LLM with a larger window is certainly an option (GPT-4 can extend to 32k tokens), but as mentioned earlier will quadratically increase the amount of compute, time and cost needed to complete the task, hence in such applications it may be more appropriate to fine-tune the LLM, despite the initial outlay.
Model size is yet another factor that needs to be considered. Pre-training a domain-specific LLM, or fine-tuning a small foundational model (such as GPT-3.5 Turbo) can often match or even outperform prompting a larger foundation equivalent (such as GPT-4) whilst being smaller and requiring fewer examples to contextualise the prompt (by up to 90%) and hence cheaper to run.
Of course, fine-tuning and prompt engineering are not mutually exclusive, so there may be some benefit in fine-tuning a model generically for the domain, and then using it to develop solutions for each task via a combination of in-context learning and instruction prompting.
In particular, fine-tuning doesn’t increase domain-level knowledge, so reducing hallucinations might require adopting techniques such as instruction prompting, in-context learning and RAG/embedding, the latter also being beneficial where responses need to be verifiable for legal or regulatory reasons.
Essentially, the choice of approach will very much come down to use case. If the aim is to deliver a natural language search/recommendation capability for use with Enterprise data, a good approach would be to employ semantic embeddings within a RAG framework. Such an approach is highly scalable for dealing with a large database of documents, and able to retrieve more relevant content (via vector search) as well as being more cost-effective than fine-tuning.
Conversely, in the case of a Customer Support chatbot, fine-tuning the model to exhibit the right behaviours and tone of voice will be important, and could then be combined with in-context learning/RAG to ensure the information it has access to is up-to-date.
Choosing a foundational LLM
There are a range of foundational models to choose from with well-known examples coming from OpenAI (GPT-3.5), Google (PaLM 2), Meta (LLama2), Anthropic (Claude 2), Cohere (Command), Databricks (Dolly 2.0), and Israel’s AI21 Labs, plus an increasingly large array of open source variants that have often been fine-tuned towards particular skillsets.
Deployment on-prem provides the Enterprise with more control and privacy, but increasingly a number of players are launching cloud-based solutions that enable Enterprises to fine-tune a model without comprising the privacy of their data (in contrast to the public use of ChatGPT, for example).
OpenAI, for instance, have recently announced availability for fine-tuning on GPT-3.5 Turbo, with GPT-4 coming later this year. For a training file with 100,000 tokens (e.g., 50 examples each with 2000 tokens), the expected cost might be as little as ~$2.40, so experimenting with fine-tuning is certainly within the reach of most Enterprises albeit with the ongoing running costs of using OpenAI’s APIs for utilising the GPT model.
If an Enterprise doesn’t need to fine-tune, OpenAI now offer ChatGPT Enterprise, based on GPT-4, and with an expanded context window (32k tokens), better performance (than the public ChatGPT) and guaranteed security for protecting the Enterprise’s data.
Alternatively, Microsoft have teamed up with Meta to support Llama 2 on Azure and Windows, and for those that prefer more flexibility, Hugging Face has become by far the most popular open source library to train and fine-tune LLMs (and other modalities).
As mentioned previously, players are also bringing to market LLMs pre-trained for use within a particular domain; for example: BloombergGPT for finance; Google’s Med-PaLM-2 for helping clinicians determine medical issues within X-rays and Sec-PaLM which was tweaked for cybersecurity use cases; Salesforce’s XGen-7B family of LLMs for sifting through lengthy documents to extract data insights, or their Einstein GPT (based on ChatGPT) for use with CRM; IBM’s watsonx.ai geospatial foundation model for Earth observation data; AI21 Labs hyper-optimized task-specific models for content management or expert knowledge systems; Harvey AI for generating legal documents etc.
‘Agents’ take the capabilities of LLMs further still by taking a stated goal from the user and combining LLM capabilities with search and other functionality to complete the task – there are a number of open source projects innovating in this area (AutoGPT, AgentGPT, babyagi, JARVIS, HuggingGPT), but also commercial propositions such as Dust.
It’s a busy space… so what are the opportunities (if any) for startups to innovate and claim a slice of the pie?
Uncovering the opportunities
Perhaps not surprisingly given the rapid advancements that have been achieved over the past 12mths, attention in the industry has very much focused on deriving better foundational models and delivering the immense compute resources and data needed to train them, and consequently has created eye-wateringly high barriers for new entrants (Inflection AI recently raising $1.3bn to join the race).
Whilst revenues from offering foundational models and associated services look promising (if you believe the forecasts that OpenAI is set to earn $1bn over the next 12mths), value will also emerge higher up the value stack, building on the shoulders of giants so to speak, and delivering solutions and tools targeted towards specific domains and use cases.

Success at this level will be predicated on domain experience as well as delivering a toolchain or set of SaaS capabilities that enable Enterprises to quickly embrace LLMs, combine them with their data, and generate incremental value and a competitive advantage in their sector.
In stark contrast to the Big Data and AI initiatives in the past that have delivered piecemeal ‘actionable insights’, LLMs have the potential of unlocking comprehensive intelligence, drawing on every documented aspect of a given business, and making it searchable and accessible through natural language by any employee rather than being constrained by the resources of corporate Business Intelligence functions.
But where might startups go hunting for monetisable opportunities?
One potential option is around embeddings – noisy, biased, or poorly-formatted data can lead to suboptimal embeddings resulting in reduced performance, so is a potential micro-area for startups to address: developing a proposition, backed-up with domain-specific experience, and crafting an attractive niche in the value chain helping businesses in targeted sectors.
Another area is around targeted, and potentially personalised, augmentation tools. Whilst the notion of GenAI/LLMs acting as copilots to augment and assist humans is often discussed in relation to software development (GitHub Copilot; StarCoder), it could equally assist workers across a multitude of everyday activities. Language tasks are estimated to account for 62% of office workers’ time, and hence there is in theory huge scope for decomposing these tasks and automating or assisting them using LLM copilots. And just as individuals personalise and customise their productivity tools to best match their individual workflows and sensibilities, the same is likely to apply for LLM copilots.
Many expect that it will turn into an AI gold rush, with those proving commercial value (finding the gold) or delivering the tools to help businesses realise this value (picks & shovels) earning early success and with a chance of selling out to one of the bigger players keen to do a land grab (e.g., Salesforce, Oracle, Microsoft, GCP, AWS etc.) and before the competition catches up.
Defensibility though is likely to be a challenge, at least in the pure sense of protecting IP, and perhaps is reserved for those with access to domain-specific data sets that gives them an edge – Bloomberg, for instance, had the luxury of training their GPT model using their own repository of financial documents spanning forty years (a massive 363 billion tokens).
Takeaways
Foundational LLMs have come a long way, and can be used across a dazzling array of natural language tasks.
And yet when it comes to Enterprise applications, their knowledge is static and therefore out of date, they’re unable to state their source (given the statistical nature of how LLMs produce outputs), and they’re liable to deliver incorrect factual responses (hallucinations).
To do well in an Enterprise setting they need to be provided with detailed and appropriate context, and adequately guided.
Industry and academia are now working diligently to address these needs, and this article has outlined some of the different techniques being developed and employed.
But LLMs are still an immature technology, hence developers and startups that understand the technology in depth are likely to be the ones best able to build more effective applications, and build them faster and more easily, than those who don’t – this, perhaps, is the opportunity for startups.
As stated by OpenAI’s CEO Sam Altman, “Writing a really great prompt for a chatbot persona is an amazingly high-leverage skill and an early example of programming in a little bit of natural language”.
We’re entering the dawn of natural language programming…
