Executive summary
AI has exploded onto the scene, capturing the imagination of the public and investment community alike, and with many seeing it as transformative in driving future economic growth. Certainly, it’s finding its way into all manner of devices and services.
But its thirst for data and generative capabilities across all modalities (text, images, audio, video etc.) will drive a need for a more hyperconnected compute fabric encompassing sensing, connectivity, processing and flexible storage. Addressing these needs will likely be dependent on a paradigm shift away from just connecting things, to enabling “connected intelligence”. Future networks will need to get ‘smarter’, and will likely only achieve this by embracing AI throughout.
Emergence of AI
Whilst AI has been around for 70 years, recent advances in compute combined with the invention of the Transformer ML architecture and an abundance of Internet-generated data has enabled AI performance to advance rapidly; the launch of ChatGPT in particular capturing worldwide public interest in November 2022 and heralding AI’s breakout year in 2023.
Many now regard AI as facilitating the next technological leap forward, and it has been recognised as a crucial technology within the UK Science & Technology Framework.
But how transformative will AI really be?
Sundar Pichai, CEO Alphabet believes “AI will have a more profound impact on humanity than fire, electricity and the internet”, whilst Bill Gates sees it as “the most important advance in technology since the graphical user interface”.
Investor sentiment has also been very positive, AI being the only sector within Deep Tech to increase over the past year, spurred on by the emergence of Generative AI (GenAI).
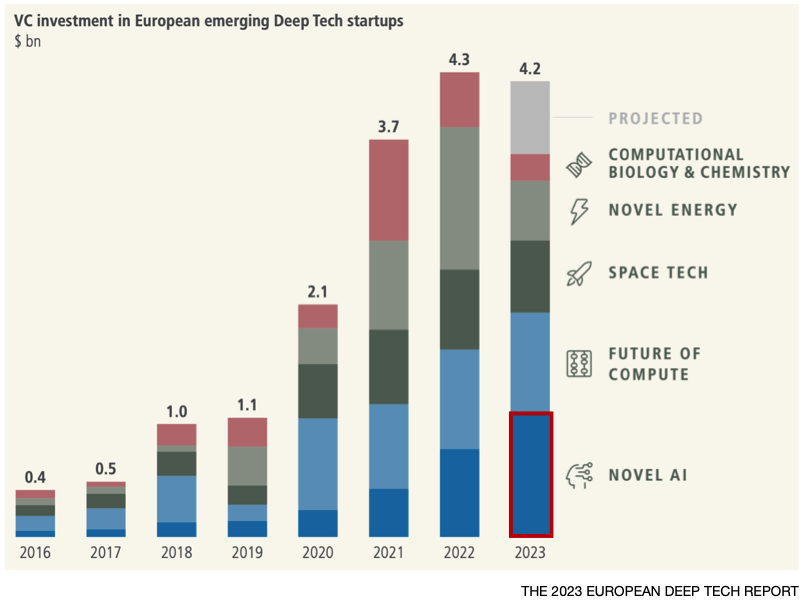
But is GenAI just another bubble?
The autonomous vehicle sector was in a similar position back in 2021, attracting huge investment at the time but ultimately failing to deliver on expectations.
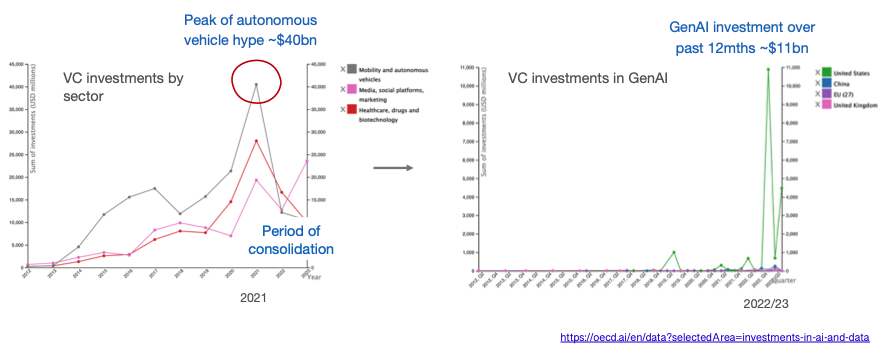
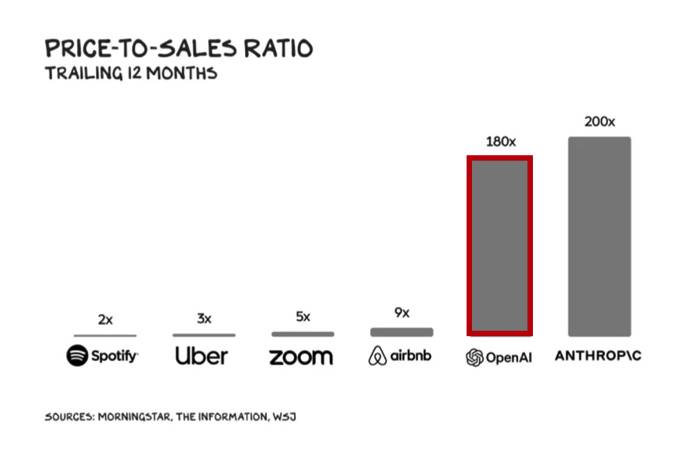
In comparison, commercialisation of GenAI has gotten off to an impressive start with OpenAI surpassing $2bn of annualised revenue and potentially reaching $5 billion+ this year, despite dropping its prices massively as performance improved – GPT3 by 40x; GPT3.5 by 10x with another price reduction recently announced, the third in a year.
On the back of this stellar performance, OpenAI is raising new funding at a $100bn valuation ~62x its forward revenues.
Looking more broadly, the AI industry is forecast to reach $2tn in value by 2030, and contribute more than $15 trillion to the global economy, fuelled to a large extent by the rise of GenAI.
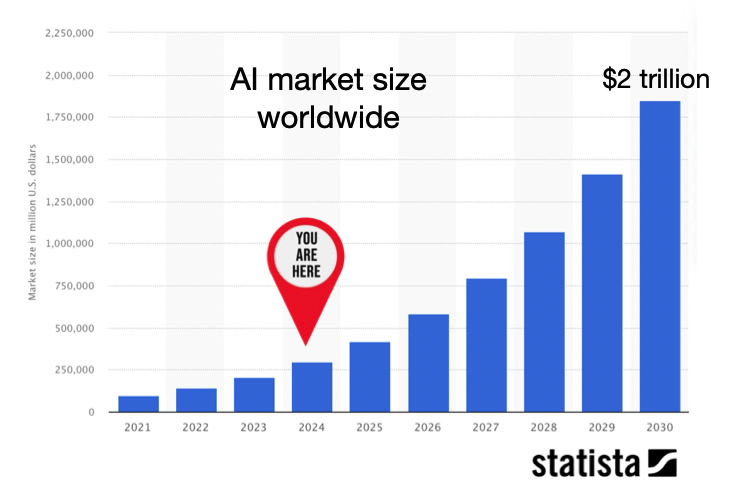
Whilst undeniably value creating, there is concern around AI’s future impact on jobs with the IMF predicting that 40% may be affected, and even higher in advanced economies. Whether this results in substantial job losses remains a point of debate, the European Central Bank concluding that in the face of ongoing development and adoption, “most of AI’s impact on employment and wages – and therefore on growth and equality – has yet to be seen”.
Future services enabled/enhanced by AI
Knowledge workers
GenAI has already shown an impressive ability to create new content (text, pictures, code) thereby automating, augmenting, and accelerating the activities of ‘knowledge workers’.
These capabilities will be applied more widely to the Enterprise in 2024, as discussed in Microsoft’s Future of Work report, and also extend to full multimodality (text, images, video, audio etc.), stimulating an uptick in more spatial and immersive experiences.
Spatial & immersive experiences (XR)
The market for AR/VR headsets has been in decline but likely to get a boost this year with the launch of Meta’s Quest 3 and Apple’s Vision Pro ‘spatial computer’.
Such headsets, combined with AI, enable a range of applications including:
- Enabling teams to collaborate virtually on product development
- Providing information for engineers in the field – e.g., Siemens and Sony
- Simulating realistic scenarios for training purposes (such as healthcare)
- Showcasing products (retail) and enabling new entertainment & gaming experiences
The Metaverse admittedly was over-hyped, but enabling users to “see the world differently” through MR/AR or “see a different world” through VR is expected to boost the global economy by $1.5tn.
Cyber-physical & autonomous systems
Just as AI can help bridge the gap for humans between the physical and the digital, GenAI can also be used to create digital twins for monitoring, simulating and potentially controlling complex physical systems such as machinery.
AI will also be used extensively in robotics and other autonomous systems, enhancing the computer vision and positioning & navigation (SLAM) of smart robots in factories, warehouses, ports, and smart homes with predictions that 80% of humans will engage with them daily by 2030.
Personal devices
And finally, AI is already prevalent in many personal devices; in future, “Language models running on your personal device will become your very personal AI assistant”.
Connected Intelligence
These future services will drive a shift to more data being generated at the edge within end-user devices or in the local networks they interface to.
As the volume and velocity increases, relaying all this data via the cloud for processing becomes inefficient, costly and reduces AI’s effectiveness. Moving AI processing at or near the source of data makes more sense, and brings a number of advantages over cloud-based processing:
- improved responsiveness – vital in smart factories or autonomous vehicles where fast reaction time is mission critical
- increased data autonomy – by retaining data locally thereby complying with data residency laws and mitigating many privacy and security concerns
- minimising data-transfer costs of moving data in/out of the cloud
- performing continuous learning & model adaptation in-situ
Moving AI processing completely into the end-user device may seem ideal, but presents a number of challenges given the high levels of compute and memory required, especially when utilising LLMs to offer personal assistants in-situ.
Running AI on end-user devices may therefore not always be practical, or even desirable if the aim is to maximise battery life or support more user-friendly designs, hence AI workloads may need to be offloaded to the best source of compute, or perhaps distributed across several, such as a wearable offloading AI processing to an interconnected smartphone, or a smartphone leveraging compute at the network edge (MEC).
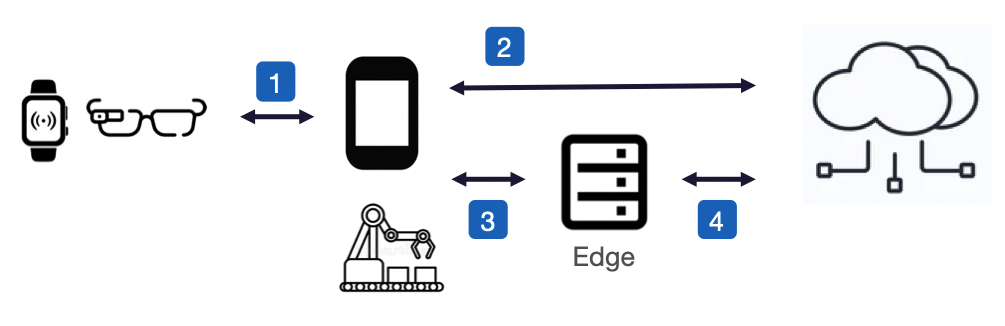
Future networks, enabled by AI
Future networks will need to evolve to support these new compute and connectivity paradigms and the diverse requirements of all the AI-enabled services outlined.
5G Advanced will meet some of the connectivity needs in the near-term, such as low latency performance, precise timing, and simultaneous multi-bearer connectivity. But going forward, telecoms networks will need to become ‘smarter’ as part of a more hyperconnected compute fabric encompassing sensing, connectivity, processing and flexible storage.

Natively supporting AI within the network will be essential to achieving this ‘smartness’, and is also the stated aim for 6G. A few examples:
Hardware design
AI/ML is already used to enhance 5G Advanced baseband processing, but for 6G could potentially design the entire physical layer.
Network planning & configuration
Network planning & configuration is increasing in complexity as networks become more dense and heterogeneous with the move to mmWave, small cells, and deployment of neutral host and private networks. AI can speed up the planning process, and potentially enable administration via natural language prompts (Optimisation by Prompting (OPRO); Google DeepMind).
Network management & optimisation
Network management is similarly challenging given the increasing network density and diversity of application requirements, so will need to evolve from existing rule-based methods to an intent-based approach using AI to analyse traffic data, foresee needs, and manage network infrastructure accordingly with minimal manual intervention.
Net AI, for example, use specialised AI engines to analyse network traffic accurately in realtime, enabling early anomaly detection and efficient control of active radio resources with an ability to optimise energy consumption without compromising customer experience.
AI-driven network analysis can also be used as a more cost-effective alternative to drive-testing, or for asset inspection to predict system failures, spot vulnerabilities, and address them via root cause analysis and resolution.
In future, a cognitive network may achieve a higher level of automation where the human network operator is relieved from network management and configuration tasks altogether.
Network security
With the attack surface potentially increasing massively to 10 million devices/km2 in 6G driven by IoT deployments, AI will be key to effective monitoring of the network for anomalous and suspicious behaviour. It can also perform source code analysis to unearth vulnerabilities prior to release, and thereby help mitigate against supply chain attacks such as experienced by SolarWinds in 2020.
Energy efficiency
Energy consumption can be as high as 40% of a network‘s OPEX, and contribute significantly to an MNO’s overall carbon footprint. With the mobile industry committing to reducing carbon emissions by 2030 in alignment with UN SDG 9, AI-based optimisation in conjunction with renewables is seen as instrumental to achieving this.
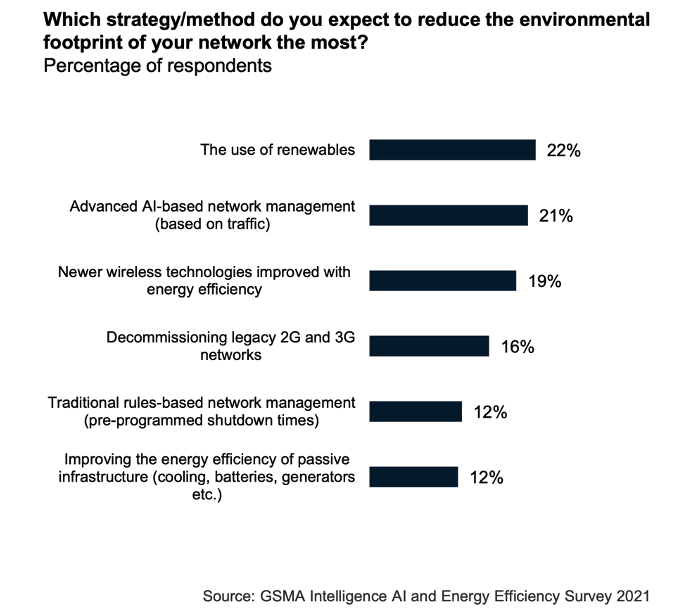
Basestations are the ‘low-hanging fruit’, accounting for 70-80% of total network energy consumption. Through network analysis, AI is able predict future demand and thereby identify where and when parts of the RAN can be temporarily shut down, maintaining the bare-minimum network coverage and reducing energy consumption in the process by 25% without adversely impacting on perceived network performance.
Turkcell, for example, determined that AI was able to reduce network energy consumption by ~63GWh – to put that into context, it’s equivalent to the energy required to train OpenAI’s GPT-4.
Challenges
Applying AI to the operations of the network is not without its challenges.
Insufficient data is one of the biggest constraints, often because passive infrastructure such as diesel generators, rectifiers and AC, and even some network equipment, are not IP-connected to allow access to system logs and external control. Alternatively, there may not be enough data to model all eventualities, or some of the data may remain too privacy sensitive even when anonymised – synthesising data using AI to fill these gaps is one potential solution.
Deploying the AI/ML models themselves also throws up a number of considerations.
Many AI systems are developed and deployed in isolation and hence may inadvertently work against one another; moving to multi-vendor AI-native networks within 6G may compound this issue.
The AI will also need to be explainable, opening up the AI/ML models’ black-box behaviour to make it more intelligible to humans. The Auric framework that AT&T use for automatically configuring basestations is based on decision trees that provide a good trade-off between accuracy and interpretability. Explainability will also be important in uncovering adversarial attacks, either on the model itself, or in attempts to pollute the data to gain some kind of commercial advantage.
Skillset is another issue. Whilst AI skills are transferable into the telecoms industry, system performance will be dependent on deep telco domain knowledge. Many MNOs are experimenting in-house, but it’s likely that AI will only realise its true potential through greater collaboration between the Telco and AI industries; a GSMA project bringing together the Alan Turing Institute and Telenor to improve Telenor’s energy efficiency being a good example.

Perhaps the biggest risk is that the ecosystem fails to become sufficiently open to accommodate 3rd party innovation. A shift to Open RAN principles combined with 6G standardisation, if truly AI-native, may ultimately address this issue and democratise access. Certainly there are a number of projects sponsored within the European Smart Networks and Services Joint Undertaking (SNS JU) such as ORIGAMI that have this open ecosystem goal in mind.
Takeaways
The global economy today is fuelled by knowledge and information, the digital ICT sector growing six times faster than the rest of the economy in the UK – AI will act as a further accelerant.
Achieving its full potential will be dependent on a paradigm shift away from just connecting things, to enabling “connected intelligence”. Future networks will need to get ‘smarter’, and will likely only achieve this by embracing AI throughout.
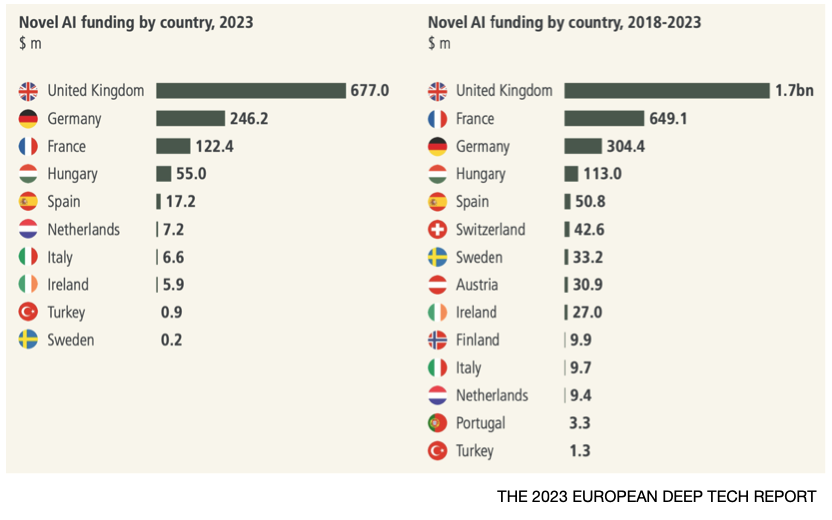
The UK is a leader in AI investment within Europe; but can it harness this competence to successfully deliver the networks of tomorrow?
The computing landscape is one of constant change and the move to cloud has arguably been the most transformative in recent years. Early concerns around security have given way to adoption – according to Cisco’s (2022), 82% of businesses now routinely use hybrid cloud. Ironically they found it’s often security concerns driving a hybrid-cloud approach by giving teams the ability to selectively place workloads in public clouds while keeping others on-prem, or using different regions to meet data residency requirements.
But with players such as AWS, GCP and Azure creating a stranglehold on the market, there is growing awareness and a movement away from becoming too dependent on any single Cloud Service Provider (CSP), instead taking a multi-cloud approach.
Decentralisation is currently du jour in many aspects of the online world, most notably in finance (DeFi), and is starting to gain attention in the compute space through companies such as StorJ, Akash and Threefold – in essence, a blockchain-enabled approach that harnesses distributed compute & storage and will no doubt contribute to the Web3 scaffolding that underpins the future metaverse.
But decentralisation is a radical approach, and only suited to particular applications. For most enterprises today, the focus is on successfully migrating their apps into the cloud, and employing services from multiple CSPs to mitigate the dangers of becoming overly reliant on any single provider. But as many are discovering, taking a multi-cloud approach brings its own complications.
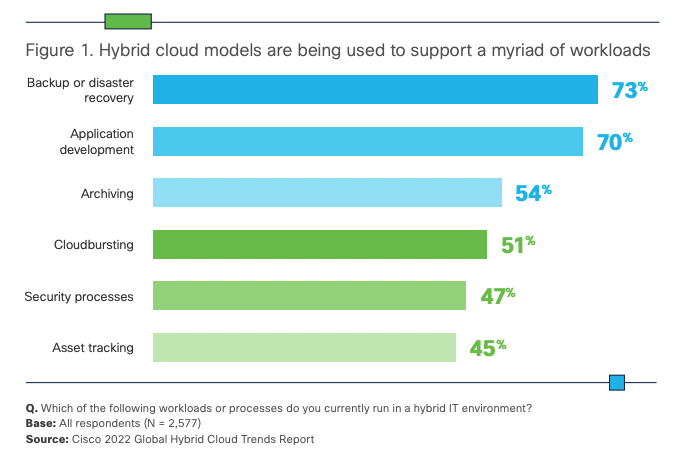
This article looks at some of the considerations and challenges that enterprises face when migrating to multi-cloud, and the resources that are out there to help them.
Cloud exuberance is over
Much has been said regarding the benefits of migrating enterprise apps to the cloud: more agility and flexibility in gaining access to resources as and when needed; an ability to scale rapidly in accordance with business needs; enabling apps hosted on-prem to burst into the cloud to accelerate workload completion time and/or generate insights with more depth and accuracy.
But it’s not all plain sailing, the hype surrounding the cloud often hides a number of drawbacks that have resulted in many businesses failing to realise the benefits expected – a recent study by Accenture Research found that only one in three companies reported achieving their cloud aims.
“Lift and shift” of legacy apps to the cloud doesn’t always work due to issues around data gravity, sovereignty, compliance, cost, and interdependencies; or perhaps because the app itself has been optimised to a specific hardware and OS used on-prem that isn’t readily available at scale in the cloud. This problem is further exacerbated by enterprises needing to move to a multi-cloud architecture.
Many believe that utilising cloud resources has a lower total cost of ownership than operating on-prem. But this doesn’t always materialise and depends on the type of systems, apps and workloads that are being considered for migration.
In the case of high performance compute (HPC) which is increasing in importance for deep learning models, simulations and complex business decisioning, enterprises running these tasks on their own infrastructure commonly dimension for high utilisation (70-90%) whereas pricing in the cloud is often orientated towards SaaS-based apps where hardware utilisation is typically <20%.
For many enterprises therefore, embarking on a programme of modernisation often results in getting caught in the middle, struggling to reach their transformation goals amidst a complex dual operating environment with some systems migrated to the cloud whilst others by necessity stay on-prem.
Optimising workloads for the cloud
For those workloads that are migrated to the cloud, delivering on the cost & performance targets set by the enterprise will be dependent on real-time analysis of workload snapshots, careful selection of the most appropriate instance types, and optimisation of the workloads to the instances that are ultimately used.
Achieving this requires a comprehensive understanding of all the compute resources available across the CSPs (assuming a multi-cloud approach), being able to select the best resource type(s) and number of instances for a given workload and SLA requirements (resilience, time, budget). In addition, where spot/pre-emptible instances are leveraged, workload data needs to be replicated between the CSPs and locations hosting the spot instances to ensure availability.
Once the target instance types are known, workload performance can be tuned using tools such as Granulate that optimise OS-level scheduling and resource management to improve performance (up to 40-60%), especially for those instances leveraging new silicon.

Similarly, companies such as CloudFix help enterprises ensure their AWS instances are auto-updated with the latest patches to deliver a more compliant cloud that performs better and costs less by removing the effort of applying manual fixes.
Spot instances offered by the CSPs at a discount are ideal for loosely coupled HPC workloads, and often instrumental in helping enterprises hit their targets on performance and cost; but navigating the vast array of instance types and pricing models is far from trivial.
Moreover, prices often fluctuate based on demand, availability, and region. 451 Research’s Cloud Price Index (CPI) for instance recorded more than 1.2 million service changes in 2021 (SKUs added, SKUs removed, price increases and price decreases).
So whilst spot instances can help with budgetary targets and economic viability for HPC workloads, juggling instances to optimise cost and break-even point between reserved instances, on-demand, and spot/preemptible instances, versus retaining workloads on-prem, can become a real challenge for teams to manage.
Furthermore, with spot prices fluctuating frequently and resources being reclaimed with little notice by the CSP, teams need to closely monitor cloud usage, throttling down workloads when pricing rises above budget, migrating workloads when resources are reclaimed, and tearing down resources when they’re no longer needed. This can soon become an operational and administrative nightmare.
Cloud Management Platforms
Cloud Management Platforms (CMP) aim to address this with a set of tools for streamlining operations and enabling cloud resources to be utilised more effectively.
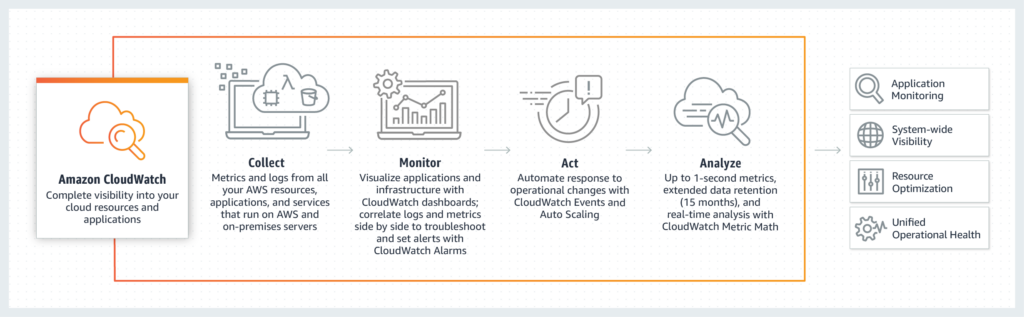
Whilst it’s true that CSPs provide such tools to aid their customers (such as AWS CloudWatch), they are proprietary in nature and vary in functionality, complicating the situation for any enterprise with multi-cloud deployments – in fact, Cisco found that a third of responding organisations highlighted operational complexity as a significant concern when adopting hybrid or multi-cloud models.
This is where CMPs come in, providing a “unified” experience and smoothing out the differences when working with multiple CSPs.
Such platforms provide an ability to:
- create clusters of mixed instance types to avoid provider lock-in and circumvent constraints imposed by any single CSP when dealing with large clusters
- manage workloads and resource provisioning simultaneously to maximise efficiency
- track progress and scheduling of all workloads via a single dashboard
- dynamically change prioritisation or allocation of resources to deliver results on time and within budget
- monitor when workloads start and complete to ensure that resources are not left running
CMPs achieve this by leveraging the disparate resources and tooling of the respective cloud providers to deliver a single homogenised set of resources for use by the enterprise’s apps.
Moreover, by unifying all elements of provisioning, scheduling and cost management within a single platform, they enable a more collaborative working relationship between teams within the organisation (FinOps). FinOps has demonstrated a reduction in cloud spend by 20-30% by empowering individual teams to manage their cloud usage whilst enabling better alignment with business metrics and strategic decision-making.
Introducing YellowDog
YellowDog is a leader in the CMP space with a focus on enterprises seeking a mix of public, private and on-prem resources for HPC workloads.
In short, the YellowDog platform combines intelligent orchestration, scheduling and dynamic policy-driven provisioning at scale across on-prem, hybrid and multi-cloud environments using agent technology. The platform has applicability ranging from containerised workloads through to supporting bare-metal servers without a hypervisor.
Compute resources are formulated into “on-demand” clusters and abstracted through the notion of workers (threads on instances). YellowDog’s Workload Manager is a cloud native scheduler that scales beyond existing technologies to millions of processor cores, working across all the CSPs, multi-region, multi-datacentre and multi-instance shapes.
It can utilise Spot type instances where others can’t, acting as both a native scheduler and meta-scheduler (invoking 3rd party technologies and creating specific workload environments such as Slurm, OpenMPI etc.) to work with both loosely coupled and tightly coupled workloads.
YellowDog’s workload manager matches workload demand with the supply of workers whilst ensuring compatibility (via YellowDog’s extensive Image Registry) and automatically reassigning workloads in case of instance removal – effectively it is “self-healing”, automatically provisioning and deprovisioning instances to match the workload queue(s).
The choice of which workers to choose is managed by the enterprise through a set of compute templates defining workload specific compute requirements, data compliance restrictions and enterprise policy on use of renewables etc. Compute templates can also be attribute-driven via live CSP information (price, performance, geographic region, reliability, carbon footprint etc.), and potentially in future with input from CPU and GPU vendors (e.g., to help optimise workloads to new silicon).
On completion, workload output can be captured in YellowDog’s Object Store Service for subsequent analysis and collection or as input to other workloads. By combining multiple storage providers (e.g. Azure Blob, Amazon S3, Google Cloud Storage) into one coherent data surface, YellowDog mitigate the issue of data gravity and ensure that data is in the right place for use within a workload. YellowDog also supports the use of other file storage technologies (e.g. NFS, Lustre, BeeGFS) for data seeding and management.
In addition, the enterprise can define pipelines that are automatically triggered when a new file is uploaded into an object store that spin up instances and work on the new file, and then shut down when the work is completed.
As jobs are running, YellowDog enables different teams to monitor their individual workloads with real-time feedback on progress and status, as well as providing an aggregate view and ability to centrally manage quotas or allowances for different clouds, users, groups and so forth.
In summary
Multi-cloud is becoming the norm, with businesses typically using >2 different providers. In fact Cisco found that 58% of those surveyed use 2-3 CSPs for their workloads, with 31% using more than 4. Effective management of these multi-cloud environments will be paramount to ensuring future enterprise growth. Cloud Management Platforms, such as that offered by YellowDog, will play an important role in helping enterprises to maximise their use of hybrid / multi-cloud.
Demand for high performance compute (HPC) on the rise
Once the stalwart of particle physicists, Formula 1 designers, and climate forecasters, the demand for HPC is rapidly going mainstream as corporates increasingly introduce deep learning models, simulations and complex business decisioning into their daily operations.
HPC can play a pivotal role in accelerating product design, tackling complex problems and enabling businesses to generate insights faster and with more depth and accuracy, and has applicability across an ever-widening range of industries including financial services, media, gaming and retail.
To-date, the only option for corporates seeking to access this level of compute was to build, maintain and operate dedicated HPC facilities in-house, but this brings a number of challenges. The first is cost – HPC systems are expensive, and only around 7% of the budget actually goes toward the hardware, the rest being consumed by buildings, staffing, power, cooling, networking etc. Moreover, because many of these systems are designed to support peak demand, utilisation can be as little as 60% for the majority of the time.
What’s more, significant additional capital is needed on a three year upgrade cycle to keep pace with demand as the business grows and the volume and complexity of workloads increases, and/or to reap the benefits of the latest computing technology. But this computing resource is intrinsically finite and hence projects within an organisation need to be prioritised leading to many missing out or having to step aside if more urgent tasks come along.
HPC on-premise deployments are traditionally designed and optimised around particular use cases (such as climate forecasting) whereas corporates today need HPC resources that can support a much broader set of applications and be able to adapt as workload characteristics evolve in reaction to the fast-moving competitive landscape.
Many companies are therefore turning to cloud-based HPC.
[Image Source: www.seekpng.com]
Benefits of cloud HPC
First and foremost, cloud HPC provides more flexibility for an organisation to gain access to HPC resources as and when needed and scale to match individual workload demands.
It also opens up more choices for the corporate; for instance, employing 10x HPC resources to accelerate product design and gain competitive advantage by being first to market. Or increasing productivity by removing compute barriers so that the corporate can use more detailed simulations or eliminate the effort in simplifying deep learning models to fit inside legacy hardware.
A cloud-based approach mitigates the risk in cost & complexity of operating HPC on-prem by providing flexibility to manage the cost/performance trade-off, allowing HPC environments to be created on the fly and then torn down as soon as the workloads have completed to avoid the corporate paying for resources and software licenses that are no longer needed.
To accommodate this variability in customer demand, CSPs dimension their cloud infrastructure with excess capacity which is powered-up and ready to use but otherwise sitting idle. To offset the monetary and environmental impact of this idle infrastructure, CSPs offer this excess capacity in the form of preemptible instances at massive discounts (up to 90% in some cases) but with the caveat that the resource can be reclaimed by the CSP at a moment’s notice if required by a full-paying customer – a corporate choosing to use these preemptible instances is essentially trading availability guarantees for a variable but much reduced ‘Spot’ price.
HPC workloads such as running a simulation, training a deep learning model, analysing a big data set or encoding video are periodic and batch in nature and not dependent on continuous availability hence a good fit for preemptible resources. If some of the resource instances within the HPC cluster are reclaimed during processing, the workload slows but does not completely stop. Ideally though, it should be possible to quickly and seamlessly re-distribute the part of the workload that was interrupted to alternate resources at the same or a different CSP thereby ensuring that the workload still completes on time – this is possible but not easy, and an area of speciality for some 3rd party tool providers.
With the increase in availability of HPC resources twinned with the ability to closely manage cost, corporates get the opportunity to open up HPC resources to the wider organisation, enabling a wider range of teams, departments and geographically dispersed business units to access the processing power they need whilst being able to track cost and performance and focus on outcomes rather than managing operational complexity.
In a world that is speeding up, becoming more competitive, and being driven by continuous integration and continuous delivery (CI/CD), easy access to cost-effective HPC resources on-the-fly is likely to become a key requirement for any corporate wishing to stay ahead.
Considerations when leveraging cloud HPC
Running complex technical workloads in the cloud is not as simple as swiping a credit card and getting a cloud account.
Many of the companies coming to cloud HPC will be specialists in their area, and may also have cloud expertise, but will need support in composing their workloads to take advantage of the parallelism within the cloud HPC stack, and tools to help them optimise their use of cloud resources.
Such tools will need to work across both workload management and resource provisioning, balancing them to meet the corporate’s target SLAs whether that be dynamically adding more resource to complete a workload on time, or prioritising and scheduling workloads to make most effective use of resources to meet budgetary constraints.
More specifically, tools will be needed that can:
Conduct realtime analysis of workload snapshots to determine their compute requirements.
Sift through the bewildering array of 30,000 different compute resources offered by the CSPs to ensure the best fit for each individual workload whilst also abiding by any corporate policy or individual budgetary targets. Factors that may need to be taken into account when selecting appropriate resources include:
- Workloads that are limited by the number of cores they can use
- Workloads that require particular processor hardware to match the OS used within a virtual image
- Workloads that may have scaling limitations due to the nature of the application licensing model provided by the software provider(s) that may not allow for bursting above a small number of processors
- Workloads that require processor hyper-threading to be disabled and/or are dependent on bare metal servers as opposed to virtual machines to maximise performance
- Tightly-coupled workloads that have specific latency and bandwidth requirements for communication between the cluster nodes
- Workloads involving sensitive data or regulatory restrictions that require all processing to be conducted within a particular locale
- Preference for cloud resources powered via renewables to meet corporate ESG targets

Create clusters of mixed instance types, and do this x-CSP to avoid vendor lock-in and/or to circumvent constraints imposed by any single CSP when dealing with large clusters.
Ensure the workload data is available in the relevant cloud by replicating data between CSPs and locations to ensure availability should a workload need to be executed there.
Monitor when workloads start and complete to ensure that resources are not left running when no workloads are executing.
Intelligently monitor spot/preemptible instances (where used) to ensure that workload cost stays within budget as the spot pricing fluctuates with demand, and reallocate workloads seamlessly if instances are reclaimed by the CSP to ensure that the composite cluster is able to deliver against the workload targets.
Integrate into a corporate’s DevOps and CI/CD processes to enable accessibility of HPC resources more broadly across the organisation.
Provide a single view of workload status and enable users to dynamically make changes to their workloads to deliver results on time and within their project budgetary constraints.
Coordinate with any 3rd party schedulers already used by the corporate (e.g., Slurm, IBM LSF, TIBCO DataSynapse GridServer etc.) to provide a single meta system for workload submission and management across on-prem, fixed cloud and public cloud HPC resources.
Client types and associated requirements
The relative importance of these different tools and requirements will very much be determined by the type of company seeking to utilise cloud HPC, the level of resources they may already have in place and the type of workloads they need to support.
Three example client types are outlined:
HPC stalwarts
Multi-national organisations and specialist corporates in sectors such as academia, engineering, life sciences, oil & gas, aircraft and automotive that already have an HPC data centre on-prem but aim to supplement it with cloud HPC resources to avoid the cost of building out and maintaining additional HPC resources themselves to increase capacity.
Such clients may use cloud resources as an extension of their existing HPC for use with all workloads, or segment and only use cloud for adhoc non-critical (and loosely coupled workloads), or perhaps just for ‘bursting’ into the cloud to deal with peaks in demand either because the planned workload exceeded expectations and bursting was needed to complete it on time (e.g., CGI rendering), or bursting was employed to speed-up execution and produce simulation results more quickly. By using the cloud as an adjunct enables these companies to extend the usefulness of their existing on-prem systems, and any new systems they deploy can be designed with less peak performance capacity by being able to burst into the cloud whenever needed.
Given that the corporate will already have on-prem and/or private cloud infrastructure, cloud HPC tools will be needed that can interface with the existing 3rd party workload schedulers. Equally, any cloud HPC resources that are employed may need to be matched to the on-prem resource types already in-use, hence intelligent tooling will be needed that can analyse individual workload requirements and provision the most appropriate cloud resources across the myriad of available instance options from the CSPs, and map the workload accordingly across the on-prem and cloud infrastructure.
Depending on the workload, the corporate may also decide to use spot/preemptible instances to complete batch processing tasks without loading other cloud resources and/or as a way of managing cost.
Cloud-native corporates
Corporates in sectors such as financial services, retail, media, gaming, manufacturing and logistics that are dependent on high-performance compute to drive their deep learning models, simulations and business decisioning to maintain a competitive edge but with insufficient funds and/or interest in deploying and managing dedicated HPC resources on-prem hence reliant on such resources being provided via the cloud.
Given the mission-critical nature of their workloads, such corporates are likely to follow a multi-cloud strategy to provide resiliency and de-risk dependency on a single provider. Selection of resources may also be driven by corporate sustainability goals, with a preference for CSPs and/or specific CSP data centres that maximise use of renewables.
Intelligent tooling will also be needed for use by the corporate in parallelising their workloads and integrating into their existing DevOps processes, and a dashboard providing oversight of HPC resources employed and workload status.
Startups/scale-ups
Similar to the cloud-native corporates, many startups/scale-ups utilising deep learning for NLP, computer vision etc. are keen on gaining access to HPC resources to accelerate their product development and time to market, and/or would like to develop products and services that can scale up and down in the cloud, but may not have the budget or expertise to achieve this.
Such companies are therefore wholly dependent on automated tools that enable them to programmatically control their usage via DevOps interfaces and dynamically switch between different CSPs and instances to minimise their costs. Primary usage will be via preemptible resources, and startups may also choose to use older generation instances to meet budgetary constraints.
Introducing YellowDog
YellowDog is a pioneer in the cloud HPC space, providing solutions that enable intelligent orchestration, scheduling and provisioning at scale across on-prem, hybrid and multi-cloud environments and delivering on all the requirements outlined above.
In addition to providing benefits to companies already employing HPC, they’re unique in being able to generate clusters delivering HPC levels of compute using spot/preemptible instances hence are well placed to support the new breed of companies needing access to HPC performance levels at an affordable price and to provide startups with a base platform that enables them to easily develop a new autoscaling product or service hence reducing their time to market and simplifying development.
A particular speciality of YellowDog is the ability to rapidly spin-up massive scale HPC clusters that aggregate resources from multiple CSPs and/or across multiple regions to circumvent the scaling limits in any particular CSP; in 2021, YellowDog successfully demonstrated creation of a cluster utilising 3.2million vCPUs on AWS to run an HPC workload with 95% utilisation, and achieved this feat in under an hour.
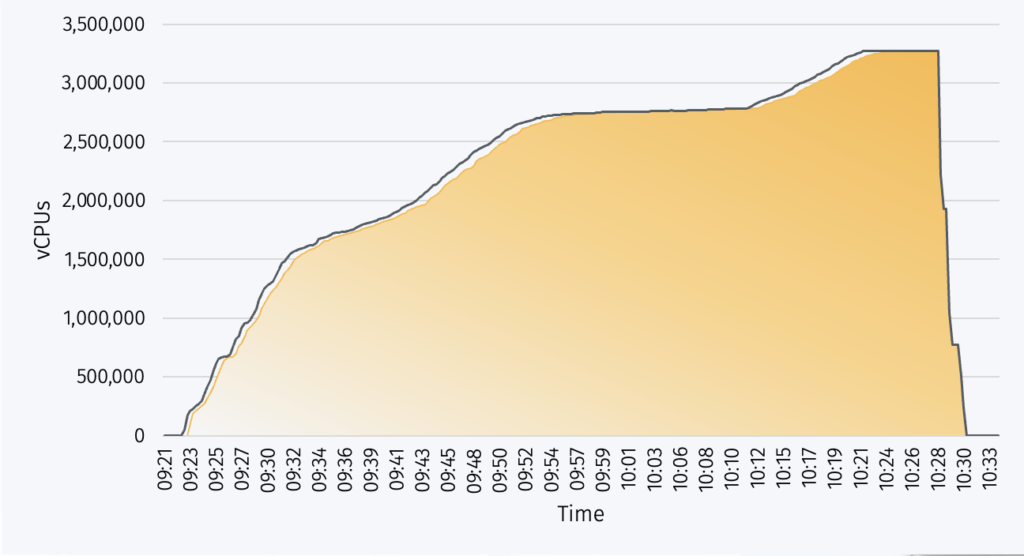
Figure 4 Scale-up to 3.2 million vCPUs and rapid scale-down on job completion (YellowDog; AWS)
The YellowDog platform provides a straightforward GUI enabling engineers and scientists to use the platform without needing to be HPC specialists, and also provides a sophisticated dashboard and API access for managing workloads and provisioning preferences, including an ML-based prediction of completion time thereby enabling customers to easily flex the resources being employed to meet a particular deadline or budgetary constraint.
Unique in the market, YellowDog also compiles a realtime insight on the myriad of different instances offered by the main CSPs[1] with regard to their machine performance, pricing, and use of renewables, and utilises this intelligence within the YellowDog platform to deliver optimal provisioning for its clients.
Whilst there are other companies offering solutions to help clients with their cloud orchestration and management, only YellowDog provide orchestration twinned with intelligent scheduling and provisioning at sufficient scale to deliver compute capabilities at HPC performance levels, and at a price point using spot/preemptible resources that meets the growing industry demand, and via a platform and set of tools that enable all to enjoy the benefits of cloud HPC.
Takeaways
The world is speeding up.
Easy access to HPC levels of compute via the cloud is changing the economics of product development, increasing the pace of innovation and enabling corporates to increase agility, accuracy, and critical insights in today’s data-driven economy. By harnessing preemptible instances and spot pricing, even the smallest of companies and startups can now afford to run HPC workloads.
Preemptible instances ensure that cloud resources do not lie idle, and bring environmental benefits as well as incremental revenues for the CSPs and lower costs for companies utilising the cloud – a veritable win:win for all, and demonstrates that HPC systems in the cloud can be cost-comparable to on-prem alternatives whilst bringing many advantages.
Harnessing the potential of cloud HPC whilst meeting all other business objectives though is no mean feat and will be dependent on intelligent tooling. YellowDog is a pioneer in this space and a perfect partner for any business looking to leverage cloud HPC resources to gain a competitive edge.
[1] Amazon Web Services (AWS), Google Cloud Platform, Microsoft Azure, Oracle Cloud Infrastructure and Alibaba
Multi-cloud management platform provider Yellowdog wins Finance Challenge award
YellowDog, the multi cloud management platform, has won the ‘People’s Choice award’ and placed 3rd overall in the UBS Future of Finance Challenge 2019.
The UBS Future of Finance Challenge 2019 was delivered in collaboration with Deloitte. It brought together 40 Fintechs that were selected from over 400 who applied from across the world.
In the ‘Foundation Setting: Technology Enablement’ category, YellowDog’s ability to change the way that financial institutions can scale, control, and optimise data processing and simulation was recognised with both the ‘People’s Choice award’ and the 3rd place finish.
YellowDog CEO and Founder Gareth Williams, and CCO, James Stevens were in New York this week to present as part of the UBS Future of Finance Challenge and accept the awards when they were announced.
Williams said: “This award is one that will certainly stand out because none of the many that we’ve won to date have been decided by C-level executives in a major Tier-1 international bank; and we were up against some stiff and impressive competition.
“YellowDog’s class-leading solution for multi- and hybrid-cloud management continues to evolve and this award is a fantastic acknowledgement of how our product solves the needs of these key customers. We’re very happy!”
