AI is transformational, but increasingly computationally intensive. Future advances will be dependent on discovering new compute methodologies that deliver step-change improvements in both speed and energy efficiency.
Could photonics be the answer?
Photons are virtually frictionless and able to travel much faster than the electrons used in digital microelectronics hence can support higher bandwidths & lower latency whilst also avoiding the resistive losses of electronics to deliver much greater energy efficiency.
This article explores the potential of photonics in the future of AI compute, and the challenges it faces in realising its commercial promise.
Photonics is a natural fit for AI computation
Due to the intrinsically linear nature of light, photonics is well suited to supporting the linear algebra used in AI computation.
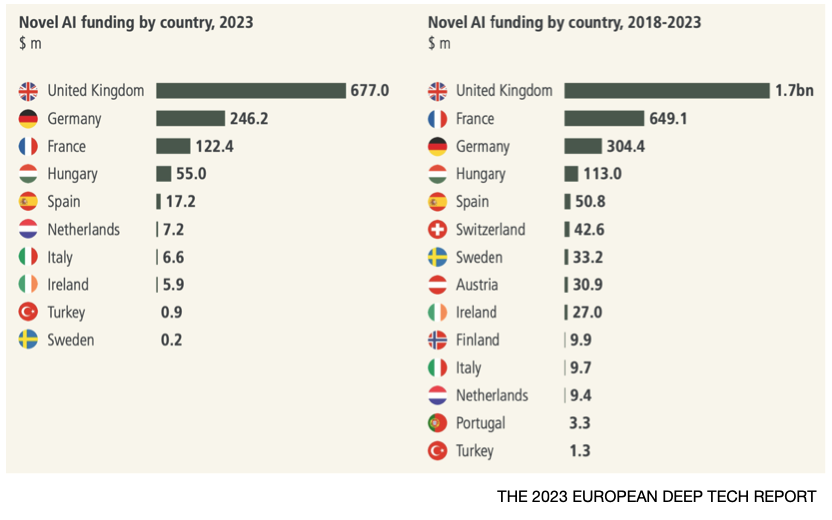
As shown in the following diagram, if two numbers x & y are encoded via the intensity of two light beams sent through a beam splitter, measuring the outputs with photodetectors, and then inverting one before summing, results in a signal proportional to the product of the two numbers (2xy) which can then be stored in a capacitor.
Source: The future of deep learning is photonic [Ryan Hamerly, IEEE Spectrum]; https://spectrum.ieee.org/the-future-of-deep-learning-is-photonic
Subsequent number pairs can be multiplied in the same way, with the products being added together by accumulating charge within the capacitor, the total charge representing the multiply-accumulate (MAC) result.
This process can also be run in parallel by utilising light beams at different wavelengths, with addition being achieved by multiplexing the light beams into a common waveguide, their total optical power representing the MAC result.
MAC computations are a major part of performing the matrix vector multiplication (MVM) used in forward propagation for ML model training and inference. Photonics therefore provides an ideal, energy-efficient way of performing these computations, either via an integrated photonic chip, or conducted in free-space, an approach being explored by Lumai.
Another promising approach pursued by researchers including MIT-based startups Lightmatter and Lightelligence is to use Mach-Zehnder interferometers (MZI) in a 2D array to manipulate light amplitude and phase to perform the matrix multiplication, and by interconnecting the MZIs in a mesh network, compute the product.
Such an approach, utilising both amplitude and phase, extends support to complex numbers thereby enabling support for signal processing in fields such as audio, radar, or communications including, for example, channel estimation where signals are represented as complex data.
In theory then, photonics should be ideal for ML computation. In practise though, scaling it to support large ML models raises a number of challenges.
Scaling photonics is problematic
To begin with, optical computation is analog and inherently imprecise. As the number of waveguides and wavelengths are scaled up, the risk of interference and crosstalk increases, as does the impact of any microscopic imperfections in fabrication with the risk of errors quickly snowballing.
The resulting output is often therefore only an approximation of the matrix multiplication, with reduced bit precision compared to digital systems, and potentially creating a ‘reality gap’ between the trained model and the actual inference output. Manufacturing the photonic chips with higher precision can help to some degree but increases complexity and cost.
Chip size is also an issue. Photonic components tend to be relatively large, limiting chip density. Given that the number of weights (photonic components) squares with the number of neurons, the required chip area for supporting large ML models starts to add up very quickly, increasing cost.
Worst still, if a photonic chip is unable to be scaled large enough to fit the entire ML model, computation requires breaking the model down into chunks and shuttling data between the chip and memory which would necessitate an optical/electrical conversion introducing latency and additional energy consumption.
It’s somewhat ironic that the intrinsic benefit of photonics in increasing the speed and energy efficiency of MVM operations makes most sense at scale, for large ML models, and yet a number of practical limitations preclude achieving this level of scale.
But this isn’t the only challenge – the linearity of light propagation is also both a blessing and a curse.
Solutions needed for non-linear operations
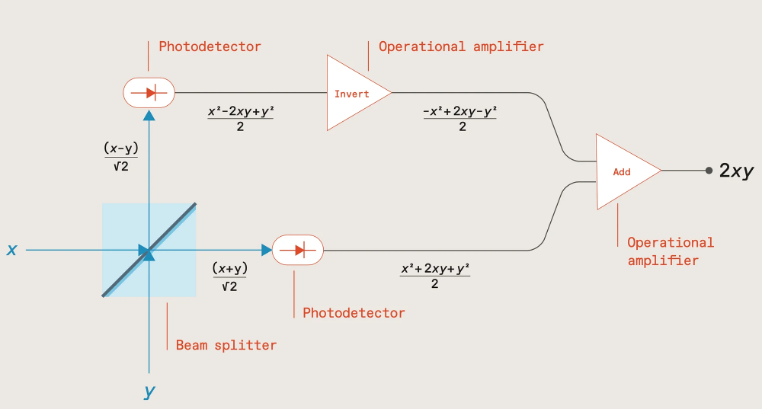
On the one hand, the linearity enables photonics to efficiently compute the weighted sums in MVM operations as we’ve already seen. But in order for ML models to learn complex patterns and represent non-linear relationships, each of these weighted sums also needs to be passed through a non-linear activation function (e.g., ReLU, sigmoid, or softmax), and there’s no easy way of achieving this in photonics.
https://medium.com/@prasanNH/activation-functions-in-neural-networks-b79a2608a106
One approach is to leverage non-linear phenomena such as the Kerr effect or saturable absorption, but these light effects are often weak and require high intensities and/or specialised materials.
Another option is to utilise non-linear modulators, or devices with quantum-dot or phase-change materials (PCM) that exhibit non-linear responses, or perhaps by employing programmable optics or photonic reservoir computing architectures. All though increase complexity and cost.
It’s far easier to simply hand off this computational aspect to digital logic; i.e., perform the linear operations (MVM) using photonics, and send the results to microelectronics for applying the non-linear activation functions.
It’s a similar situation with the process of backpropagation within ML model training which involves computation of gradients – challenging to accomplish solely in photonics, so better handed off to microelectronics.
In practise then, most photonic systems, whether for ML model training or for inference, will most likely need to take a hybrid approach combining both photonics and microelectronics.
But doing so necessitates optical/electrical conversion which introduces latency and energy overhead, as well as noise, and in the case of forward propagation would need to be carried out for each layer within the neural network hence negating much of the speed and energy improvements of conducting the MVM computations photonically in the first place.
Given the maturity of existing AI compute hardware (GPUs, TPUs, and specialised AI accelerators) and their ability to perform billions of MACs per second, photonic alternatives have simply struggled to deliver sufficient performance and cost improvements to justify being considered an attractive “socket-steal”.
For the hybrid photonic approach to become commercially viable it will need to address and improve on the optical/electrical conversion process as well as improve on the speed and energy efficiency of memory access and data movement in general.
These interconnectivity issues are not limited though to photonic systems, and have become a key limitation in all distributed computing systems and data centre networks, and especially those massively scaled for training and hosting foundational AI models which are starting to hit a ‘memory wall’.
Source: https://www.celestial.ai/technology
The energy consumption associated with shuttling data within and between chips is an escalating problem as demand increases for higher throughput and compute power, and is getting as high as 80% of the total power consumption of a processor; replacing the electronic wires with optical interconnects can improve efficiency by a factor of six.
It’s perhaps not surprising then that many of the photonic startups who originally set out to develop photonic AI accelerators and all-optical computers have turned their attention in the nearer-term to improving the speed and energy efficiency of interconnectivity.
Startups including Lightelligence, Lightmatter, Ayar Labs, Celestial AI, and Black Semiconductor are all developing a range of novel solutions for optical interconnect including graphene-based optoelectronic conversion, optical interposers for connections within and between chiplets within a single chip package, as well as chip-to-chip and node-to-node optical connectivity compatible with standards such as UCIe and CXL, and potentially delivering bandwidth an order of magnitude greater than Nvidia’s NVLink.
Fully optical solutions still on the horizon
That’s not to say that the dream of all-optical compute has been entirely forsaken…
Oxford University, for example, has been exploring ways of combining processing with collocated non-volatile memory based on PCM materials to enable photonic in-memory compute (IMC) and remove the optical/electrical overhead of data movement between the photonic chip and off-chip memory.
Achieving both high speed and low energy consumption has proved challenging, but researchers in the US and Japan have recently devised an efficient non-volatile memory cell using magneto-optical materials that’s compatible with the CMOS fabrication processes used for today’s microelectronics thereby enabling manufacture at scale.
Photonic chip density is another important area for improvement. Neurophos is employing metasurface technology to develop optical modulators 8,000 times smaller than silicon-photonic–based MZIs; more generally, membrane-based nanophotonic technologies should in future enable tens of thousands of photonic components per chip.
Other advancements include the development of very thin nanostructured surfaces that can be combined with semi-transparent mirrors for performing the MVM operations; and in a separate activity scientists have developed an integrated photonics chip capable of nonlinear operations.
Takeaways
Photonics remains a tantalising prospect, with the potential of bringing a much-needed step-change in speed and efficiency to the future of compute for AI.
Many challenges remain though in realising this promise, and doing so with sufficient scale to support large ML models, and even more so given that photonics lags the microelectronics industry in VLSI design tools, yield and manufacturing maturity.
However, with the AI chip market projected to be worth $309bn by 2030 opportunities abound for startups to tackle these challenges and carve a niche with their own innovations.
The US unsurprisingly has a strong cohort of well-funded startups in this space with the likes of Lightmatter, Lightelligence, Ayar Labs and Celestial AI amongst others; but Europe is also strong in photonics AI through startups such as Black Semiconductor and Akhetonics in Germany, and Optalysys, Salience Labs, and Lumai in the UK.
AI is advancing rapidly, and photonics is poised to play a pivotal role in shaping its future, whether that be through all-optical solutions, or nearer-term as a key component in hybrid computing systems.
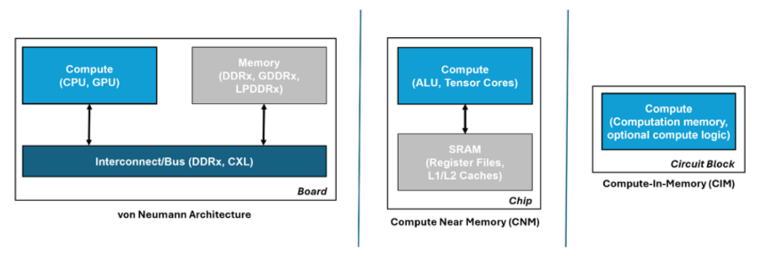
AI has been on a phenomenal rise. Artificial neural network (ANN) accelerators can be extremely performant in executing the multiply accumulate (MAC) operations needed to compute AI. However, keeping them maximally utilised requires rapidly shuttling large amounts of model data between the memory and processing units.
This becomes problematic in von Neumann architectures such as those used in ANN accelerators and modern computing in general where memory and processing are physically separated, and can quickly become a bottleneck that not only affects performance but also results in high energy consumption. In fact, data transfer is becoming more energy-consuming than the ANN computation it supports.
Moving the memory as close to the compute as possible lessens this issue and is the approach often used in ANN accelerators, either by combining memory and compute on the same die, or minimising the distance via 3D hybrid packaging. Such an approach is also popular in vision processors for resource-constrained edge devices, Hailo and Syntiant being good examples.
However, whilst this improves ANN performance, it doesn’t alleviate the bottleneck completely. A better approach, and more in keeping with neuromorphic principles, is to avoid moving the data at all, by conducting the compute operations across a memory array – in-memory compute (IMC).
Source: https://gsitechnology.com/compute-in-memory-computational-devices/
Such an approach reduces data transfers to a minimum thereby consuming orders of magnitude less energy than von Neumann architectures, and by minimising the memory bottleneck it also helps to maximise processor utilisation. Moreover, because the IMC elements act inherently as storage, realtime sensor data can be fed into them for immediate ‘through-wire’ processing for realtime edge applications.
Digital IMC
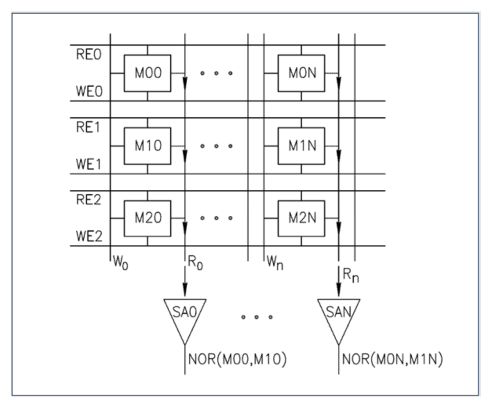
A common approach to IMC is to leverage existing mass production memory technologies such as SRAM and DRAM.
Instead of the usual practise of reading a single bit per memory row, if multiple simultaneous reads are carefully enacted it can provide a NOR function. This opens up the possibility of creating very fast Boolean logic twinned with low energy consumption using just the memory lines.
Source: https://gsitechnology.com/compute-in-memory-computational-devices/
Startups such as Synthara and UPMEM are already active in this space developing drop-in replacements for SRAM and DRAM memory chips respectively, and both only requiring minimal software updates to support them. Other startups include d-matrix and MemryX focusing on AI inference acceleration, and RAIN AI, an earlier stage startup yet to bring their solution to market but already targeting a hefty $150m round with support from Sam Altman.
Analog IMC
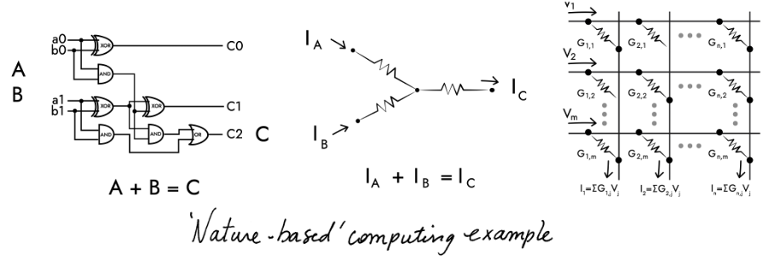
In-memory compute capabilities can also be achieved in the analog domain using a non-volatile memory array, and following a structure more closely aligned with the human brain, with each non-volatile memory element signifying a neuron and interconnections between elements forming a crossbar memory array to emulate the synapses.
Input voltages are applied along the rows of the crossbar array as shown in the diagram below. The output voltage of each neuron is multiplied by its conductance (representing the synapse weight) using Ohm’s Law, and the resulting current is summed up along each column using Kirchhoff’s Law to obtain the dot-product result, equivalent to the MAC operation mentioned earlier.
Source: https://www.aria.org.uk/wp-content/uploads/2023/11/ARIA-Unlocking-AI-compute-hardware-v1.0-1.pdf
Given that the non-volatile memory inherently maintains its state without requiring power, this approach is especially useful for AI inference in those situations where the model weights are seldom updated.
A variety of different implementation technologies are being explored by startups and other companies.
Mythic, for example, are using tuneable resistors (memristors) for the analog memory elements to target low-latency applications such as computer vision, whilst Semron have designed memcapacitive elements to avoid the intrinsic heating of memristive elements and thereby enable die stacking to support large ANNs (e.g., LLMs).
NIST and others have also explored the use of spintronics which exploits the intrinsic spin of electrons, in addition to their charge, to encode and process information. SpinEdge have developed an AI accelerator for edge devices using an array of non-volatile spintronic memory cells for storing the neural network weights.
And finally, IBM have explored the use of multi-level phase-change materials (PCMs) in their Hermes prototype chip. PCMs are particularly good for developing non-volatile memory, and with the added advantage of allowing single bits to be changed without erasing an entire block of cells, hence useful for updating individual model weights.
On the downside, given the analog nature of these different technologies, they suffer from variability across the memory elements which may require retraining of the network after it’s been loaded onto the chip.
Analog can also be limited in terms of precision, and whilst this can be improved by increasing the components’ dynamic range, noise limitations can require higher voltages, and hence higher energy consumption, thus negating the core strength of this approach versus the digital alternatives.
Another consideration is size; by putting all the weights in the crossbars, this can result in a larger chip size compared to the von Neumann approach of fetching the ANN weights as needed. It can also suffer from issues of reliability when scaling to larger systems, and poor area utilisation if the fixed memory array is larger than needed for a given ANN.
Some applications may also require interfacing with digital logic, hence requiring analog/digital conversion which will introduce latency, additional energy consumption, and potentially noise in the ADC/DAC process.
In summary, whilst analog approaches offer advantages in energy efficiency and being able to pre-load ANN models for edge deployment, they also present a number of challenges related to precision, integration, and design complexity that put them, for now, at a disadvantage to their digital equivalents.
Takeaways
As ANN models increase in size, and especially in the case of LLMs with billions of parameters, the energy and performance cost of shuttling data to and from the processing units within the classical von Neumann architecture will become an ever-increasing issue.
Storing the data closer to the processing units is one approach, with the memory elements and processing units ideally being brought together in novel architectures such as in-memory compute.
However, as noted in a previous article on neuromorphic computing, the tight integration of memory and compute might require the memory to be fabricated using the same expensive processes as the digital logic, and this can be 100x the cost of off-chip SRAM or DRAM used in conventional architectures.
And in the case of analog IMC, whilst these approaches show promise in dramatically reducing energy consumption, they also face a number of implementation challenges.
It’s therefore unlikely that in-memory compute solutions will outperform GPUs and ANN accelerators at large scale in data centres.
They are though much better suited to edge applications, such as computer vision, sensing, and robotics where their realtime capabilities are mission critical (Hailo, Syntiant), or in resource-constrained devices such as wearables (Synthara), or more generally for use across a range of edge AI applications in automotive, logistics and IoT (MemryX).
With the race to bring AI applications to the edge this is a vibrant space, and one that’s ripe for startup innovation.
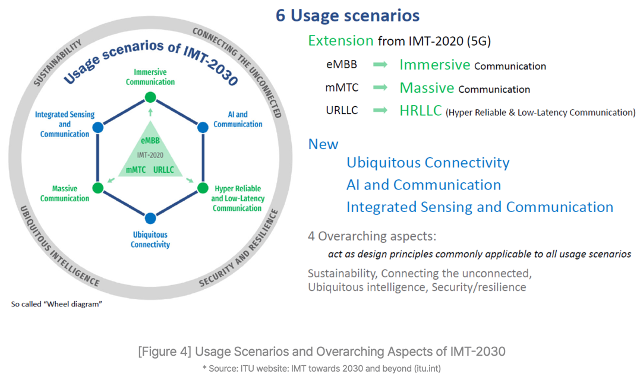
The mobile industry has been marching to the constant drum beat of defining, standardising and launching the next iteration of mobile technology every ten years or so – 3G launching in 2001, 4G in 2009, 5G in 2019, and now 6G mooted for 2030 if not before.
The ITU have laid out a set of 6G goals for the industry to work towards in the IMT-2030 framework. It builds on the existing 5G capabilities, with the aim of 6G delivering immerse, massive, hyper-reliable and low latency communications as well as increasing reach and facilitating connected intelligence & AI services.
In the past, each successive iteration has demanded wholesale upgrades of the network infrastructure – great for the telco equipment manufacturers, but ruinous for the mobile network operators (MNOs).
The GSMA and McKinsey estimate that MNOs worldwide have invested somewhere between $480 billion and $1 trillion respectively to fund the rollout of 5G. And whilst 5G has delivered faster network speeds, there are precious few examples of where 5G has delivered incremental value for the MNOs.
MNOs remain unconvinced that there are any new apps on the horizon that need ‘a new G’, and hence the likes of AT&T, Orangeand SKT amongst others have been vocal about an evolution of 5G rather than yet another step-change with 6G.
This sentiment has been further reinforced by the wider MNO community through NGMN with a clearly stated position that 6G should entail software-based feature upgrades rather than “inherently triggering a hardware refresh”.
The NGMN 6G Position Statement goes on to set a number of MNO-endorsed priorities focused primarily on network simplification with the goal of lowering operational costs, rather than the introduction of whizzy new features.
In particular, it emphasises “automating network operations and orchestration to enable efficient, dynamic service provisioning”, and “proactive network management to predict and address issues before they impact user experience”.
AI will play a pivotal role in achieving these aims. Machine learning (ML) models, for instance, could be trained on a digital twin of the physical environment and then transferred to the network to optimise it for each deployment site, radio condition, and device/user context, thereby improving performance, quality of service (QoS), and network robustness.
AI could also be used to address power consumption, another concern for MNOs, with energy costs representing as much as 40% of a network‘s OPEX according to the GSMA, and now outpacing MNO sales growth by over 50%.
By analysing traffic patterns and other factors, AI is able to make predictions on future traffic demand and thereby identify where parts of the network could be temporarily shut down, reducing energy consumption by 25% and with no adverse impact on the perceived network performance. Turkcell, for example, found that AI was able to reduce their energy consumption by ~63GWh, equivalent to the energy required by OpenAI to train GPT-4.
Startups such as Net.AI have been pioneering in this space, applying AI to improve the energy efficiency of network infrastructure, whilst EkkoSense have recently helped VM O2 save over £1 million a year in the cost of cooling its data centres, and Three have been working with Ericsson to improve energy efficiency by ~70% through the use of AI, data analytics and a ‘Micro Sleep’ feature.
Progressive MNOs such as SKT and Verizon have set out clear strategies for embracing AI, with SKT also teaming up with DT, e&, and Singtel to develop large language models for automating aspects of customer services (Telco LLM) as part of the Global Telco AI Alliance.
Given its staid image, it may be surprising to learn that telecoms is leading the adoption of GenAI (70%) ahead of both the retail (66%) and banking & insurance (60%) sectors. 89% of telcos plan to invest in GenAI next financial year – the joint highest along with the insurance industry – with application across marketing, sales and IT.
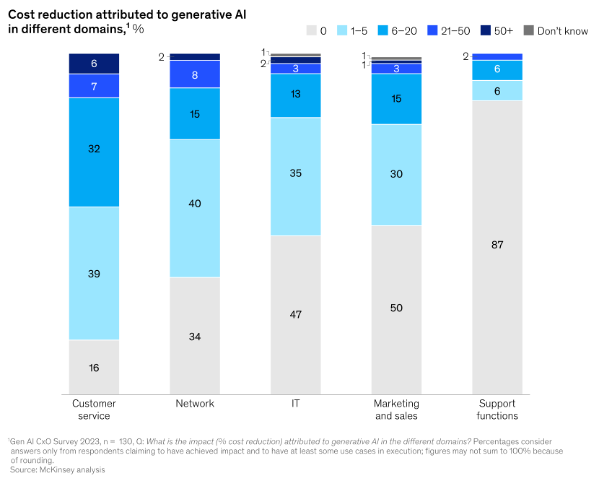
Wider adoption though of AI across all aspects of mobile won’t be easy, and certainly the integration of AI natively into future mobile networks to achieve the desired performance and energy efficiency benefits will present a few challenges.
Naysayers argue that there will be insufficient data to model all network eventualities, and that energy optimisation will be hampered given that much of the passive infrastructure at basestations (power management; air conditioning etc.) is not IP-connected.
Interoperability is another concern, particularly in the early days where AI systems are likely to be developed and deployed independently, hence creating a risk of inadvertently working against each other (e.g., maximising network performance vs shutting down parts of the network to conserve energy).
Other MNOs including Orange baulk at the cost of acquiring sufficient compute to support AI given the current purchasing frenzy around GPUs, and the associated energy cost.
This is likely to be mitigated in the longer term through combining telco and AI compute in an AI-native virtualised network infrastructure. Ericsson, T-Mobile, Softbank, NVIDIA, AWS, ARM, Microsoft, and Samsung have recently joined forces to form the AI-RAN Alliance with the goal of developing AI-integrated RAN solutions, running AI and virtualised network functions on the same compute to boost network efficiency and performance.
NVIDIA and Softbank have already run a successful pilot, demonstrating carrier-grade 5G performance on an Nvidia-accelerated AI-RAN solution whilst using the network’s excess capacity to run AI interference workloads concurrently. In doing so, they were able to unlock the two thirds of network capacity typically running idle outside of peak hours for additional monetisation, effectively turning network base stations from cost centres into AI revenue-producing assets – Nvidia and SoftBank estimate that an MNO could earn ~$5 in AI inference revenue for every $1 capex invested in new AI-RAN infrastructure.
As mentioned earlier, many MNOs are already experimenting with AI across different aspects of their network and operations. To-date, this has typically involved employing in-house resources in limited pilots.
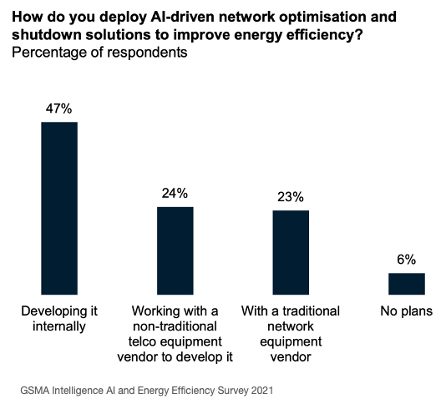
Going forward, it’s likely that AI will only realise its true potential through fostering a closer collaboration between the telecoms and AI sectors (cf. GSMA/ATI 2019), and opening up the network to embrace 3rd party innovation for tackling operational efficiency, a market potentially worth $20 billion by 2030.
This is a contentious issue though; whilst MNOs have been moving gradually towards a more open network architecture through adoption of network function virtualisation and participation in industry initiatives such as O-RAN that target network disaggregation, at an operational level many MNOs still prefer procuring from incumbent suppliers and resist any pressure to diversify their supply chain.
Taking such a stance presents a number of hurdles for startups hoping to innovate in network AI, and worst still, the lack of a validated channel-to-market disincentivises any funding of said startups by VCs.
Elsewhere, there may be other opportunities; for instance, in private 5G where solutions can be curated and optimised for individual Enterprise customers, or in the deployment of neutral host networks at public hotspots run by local councils or at stadiums – a £40m UK Gov initiative is currently underway to fund pilots in these areas.
There may also be opportunities to innovate on top of public 5G, leveraging new capabilities such as network slicing to deliver targeted solutions to particular verticals such as broadcasting and gaming, although this hinges on MNO rollout of 5G Standalone, which has been a long time coming, and making these capabilities available to developers via APIs.
MNOs have tried exposing network capabilities commercially many times in the past, either individually or through industry initiatives such as One API Exchange and the Operator Platform Group, but with little success.
MobiledgeX, an edge computing platform spanning 25 MNOs across Europe, APAC and North America was arguably more successful, but eventually acquired and subsumed into Google Cloud in 2022.
Since then, MNOs have progressively come to terms with the need to partner with the Hyperscalers, and more recently Vodafoneand BT amongst others have signed major deals with the likes of Google, Microsoft and AWS.
More interestingly, a collection of leading MNOs (Vodafone; AT&T; Verizon; Bharti Airtel; DT; Orange; Telefonica; Singtel; Reliance Jio; Telstra; T-Mobile US; and America Movil) have recently teamed up with Ericsson and Google Cloud to form a joint venture for exposing industry-wide CAMARA APIs to foster innovation over mobile networks.
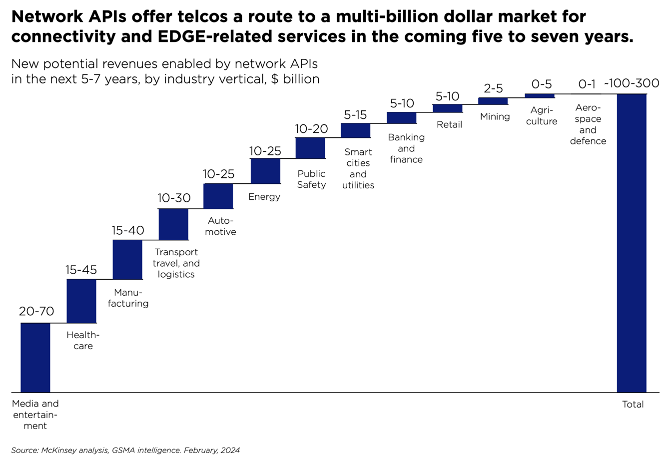
If they get it right this time, they may succeed in attracting startups and developers to the telecoms sector, and in doing so unlock a potential $300bn in monetising the network as a platform, as well as expanding their share of the worldwide $5 trillion ICT spend.
Executive summary
AI has exploded onto the scene, capturing the imagination of the public and investment community alike, and with many seeing it as transformative in driving future economic growth. Certainly, it’s finding its way into all manner of devices and services.
But its thirst for data and generative capabilities across all modalities (text, images, audio, video etc.) will drive a need for a more hyperconnected compute fabric encompassing sensing, connectivity, processing and flexible storage. Addressing these needs will likely be dependent on a paradigm shift away from just connecting things, to enabling “connected intelligence”. Future networks will need to get ‘smarter’, and will likely only achieve this by embracing AI throughout.
Emergence of AI
Whilst AI has been around for 70 years, recent advances in compute combined with the invention of the Transformer ML architecture and an abundance of Internet-generated data has enabled AI performance to advance rapidly; the launch of ChatGPT in particular capturing worldwide public interest in November 2022 and heralding AI’s breakout year in 2023.
Many now regard AI as facilitating the next technological leap forward, and it has been recognised as a crucial technology within the UK Science & Technology Framework.
But how transformative will AI really be?
Sundar Pichai, CEO Alphabet believes “AI will have a more profound impact on humanity than fire, electricity and the internet”, whilst Bill Gates sees it as “the most important advance in technology since the graphical user interface”.
Investor sentiment has also been very positive, AI being the only sector within Deep Tech to increase over the past year, spurred on by the emergence of Generative AI (GenAI).
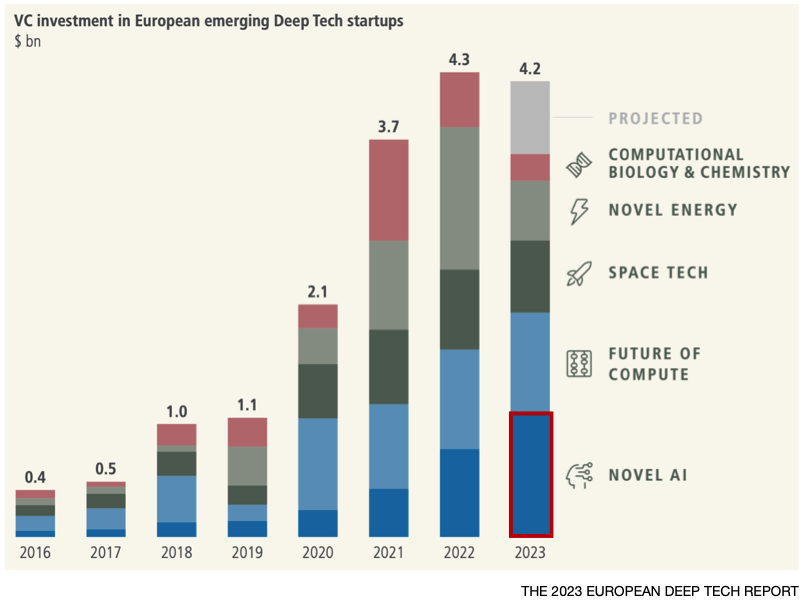
But is GenAI just another bubble?
The autonomous vehicle sector was in a similar position back in 2021, attracting huge investment at the time but ultimately failing to deliver on expectations.
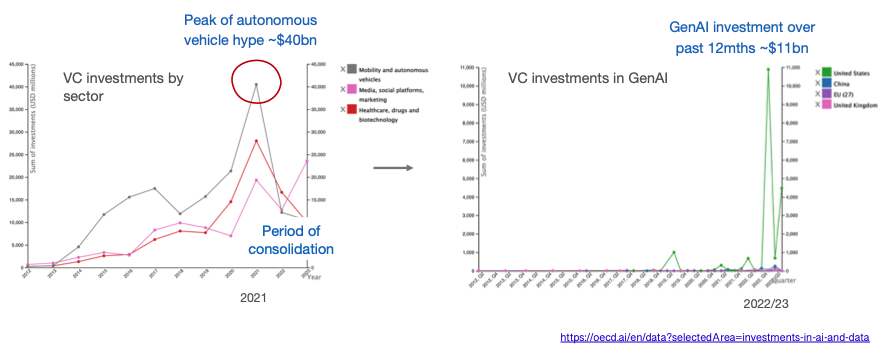
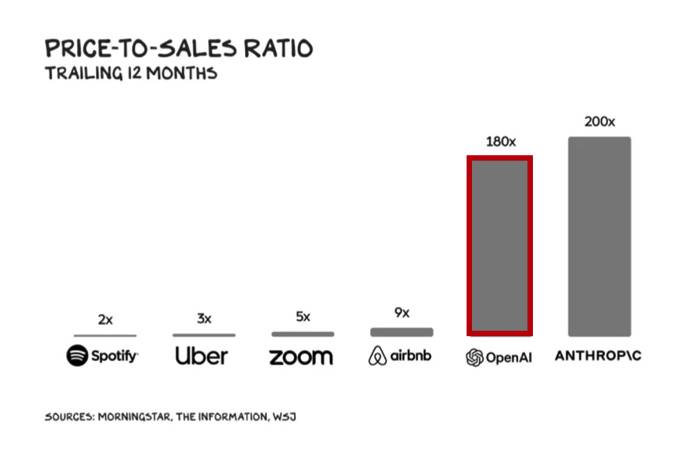
In comparison, commercialisation of GenAI has gotten off to an impressive start with OpenAI surpassing $2bn of annualised revenue and potentially reaching $5 billion+ this year, despite dropping its prices massively as performance improved – GPT3 by 40x; GPT3.5 by 10x with another price reduction recently announced, the third in a year.
On the back of this stellar performance, OpenAI is raising new funding at a $100bn valuation ~62x its forward revenues.
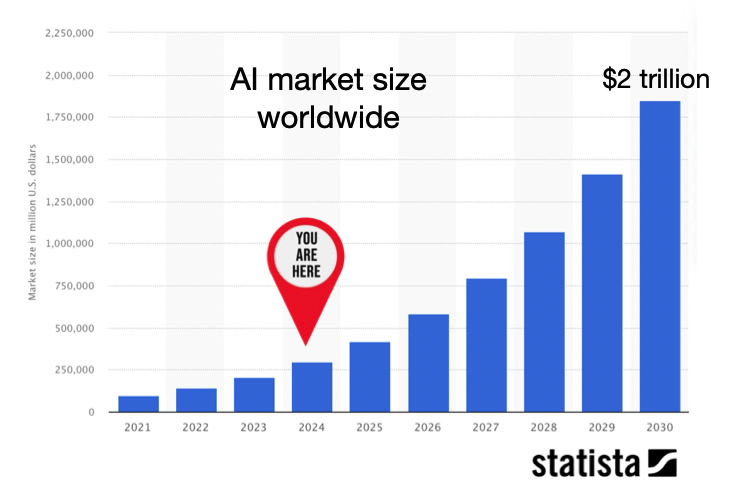
Looking more broadly, the AI industry is forecast to reach $2tn in value by 2030, and contribute more than $15 trillion to the global economy, fuelled to a large extent by the rise of GenAI.
Whilst undeniably value creating, there is concern around AI’s future impact on jobs with the IMF predicting that 40% may be affected, and even higher in advanced economies. Whether this results in substantial job losses remains a point of debate, the European Central Bank concluding that in the face of ongoing development and adoption, “most of AI’s impact on employment and wages – and therefore on growth and equality – has yet to be seen”.
Future services enabled/enhanced by AI
Knowledge workers
GenAI has already shown an impressive ability to create new content (text, pictures, code) thereby automating, augmenting, and accelerating the activities of ‘knowledge workers’.
These capabilities will be applied more widely to the Enterprise in 2024, as discussed in Microsoft’s Future of Work report, and also extend to full multimodality (text, images, video, audio etc.), stimulating an uptick in more spatial and immersive experiences.
Spatial & immersive experiences (XR)
The market for AR/VR headsets has been in decline but likely to get a boost this year with the launch of Meta’s Quest 3 and Apple’s Vision Pro ‘spatial computer’.
Such headsets, combined with AI, enable a range of applications including:
- Enabling teams to collaborate virtually on product development
- Providing information for engineers in the field – e.g., Siemens and Sony
- Simulating realistic scenarios for training purposes (such as healthcare)
- Showcasing products (retail) and enabling new entertainment & gaming experiences
The Metaverse admittedly was over-hyped, but enabling users to “see the world differently” through MR/AR or “see a different world” through VR is expected to boost the global economy by $1.5tn.
Cyber-physical & autonomous systems
Just as AI can help bridge the gap for humans between the physical and the digital, GenAI can also be used to create digital twins for monitoring, simulating and potentially controlling complex physical systems such as machinery.
AI will also be used extensively in robotics and other autonomous systems, enhancing the computer vision and positioning & navigation (SLAM) of smart robots in factories, warehouses, ports, and smart homes with predictions that 80% of humans will engage with them daily by 2030.
Personal devices
And finally, AI is already prevalent in many personal devices; in future, “Language models running on your personal device will become your very personal AI assistant”.
Connected Intelligence
These future services will drive a shift to more data being generated at the edge within end-user devices or in the local networks they interface to.
As the volume and velocity increases, relaying all this data via the cloud for processing becomes inefficient, costly and reduces AI’s effectiveness. Moving AI processing at or near the source of data makes more sense, and brings a number of advantages over cloud-based processing:
- improved responsiveness – vital in smart factories or autonomous vehicles where fast reaction time is mission critical
- increased data autonomy – by retaining data locally thereby complying with data residency laws and mitigating many privacy and security concerns
- minimising data-transfer costs of moving data in/out of the cloud
- performing continuous learning & model adaptation in-situ
Moving AI processing completely into the end-user device may seem ideal, but presents a number of challenges given the high levels of compute and memory required, especially when utilising LLMs to offer personal assistants in-situ.
Running AI on end-user devices may therefore not always be practical, or even desirable if the aim is to maximise battery life or support more user-friendly designs, hence AI workloads may need to be offloaded to the best source of compute, or perhaps distributed across several, such as a wearable offloading AI processing to an interconnected smartphone, or a smartphone leveraging compute at the network edge (MEC).
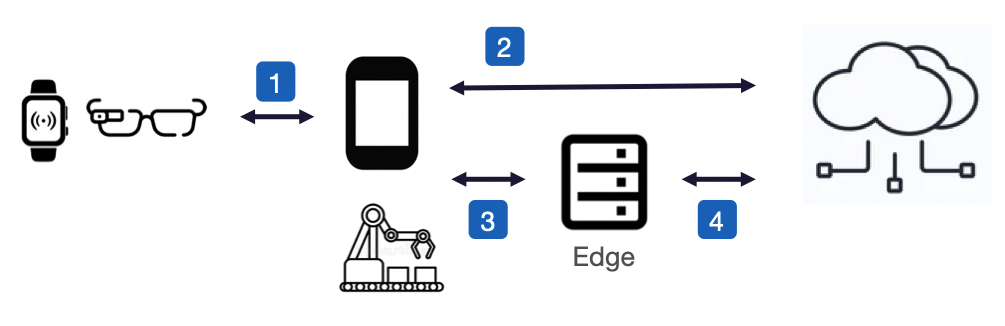
Future networks, enabled by AI
Future networks will need to evolve to support these new compute and connectivity paradigms and the diverse requirements of all the AI-enabled services outlined.
5G Advanced will meet some of the connectivity needs in the near-term, such as low latency performance, precise timing, and simultaneous multi-bearer connectivity. But going forward, telecoms networks will need to become ‘smarter’ as part of a more hyperconnected compute fabric encompassing sensing, connectivity, processing and flexible storage.

Natively supporting AI within the network will be essential to achieving this ‘smartness’, and is also the stated aim for 6G. A few examples:
Hardware design
AI/ML is already used to enhance 5G Advanced baseband processing, but for 6G could potentially design the entire physical layer.
Network planning & configuration
Network planning & configuration is increasing in complexity as networks become more dense and heterogeneous with the move to mmWave, small cells, and deployment of neutral host and private networks. AI can speed up the planning process, and potentially enable administration via natural language prompts (Optimisation by Prompting (OPRO); Google DeepMind).
Network management & optimisation
Network management is similarly challenging given the increasing network density and diversity of application requirements, so will need to evolve from existing rule-based methods to an intent-based approach using AI to analyse traffic data, foresee needs, and manage network infrastructure accordingly with minimal manual intervention.
Net AI, for example, use specialised AI engines to analyse network traffic accurately in realtime, enabling early anomaly detection and efficient control of active radio resources with an ability to optimise energy consumption without compromising customer experience.
AI-driven network analysis can also be used as a more cost-effective alternative to drive-testing, or for asset inspection to predict system failures, spot vulnerabilities, and address them via root cause analysis and resolution.
In future, a cognitive network may achieve a higher level of automation where the human network operator is relieved from network management and configuration tasks altogether.
Network security
With the attack surface potentially increasing massively to 10 million devices/km2 in 6G driven by IoT deployments, AI will be key to effective monitoring of the network for anomalous and suspicious behaviour. It can also perform source code analysis to unearth vulnerabilities prior to release, and thereby help mitigate against supply chain attacks such as experienced by SolarWinds in 2020.
Energy efficiency
Energy consumption can be as high as 40% of a network‘s OPEX, and contribute significantly to an MNO’s overall carbon footprint. With the mobile industry committing to reducing carbon emissions by 2030 in alignment with UN SDG 9, AI-based optimisation in conjunction with renewables is seen as instrumental to achieving this.
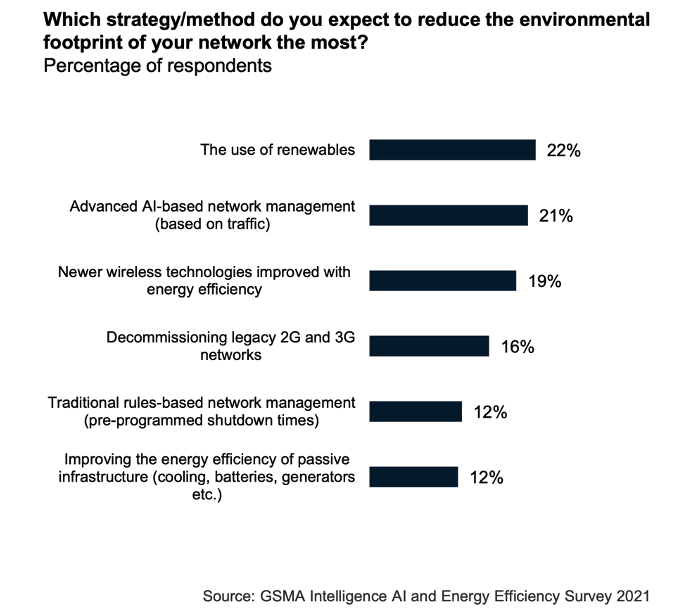
Basestations are the ‘low-hanging fruit’, accounting for 70-80% of total network energy consumption. Through network analysis, AI is able predict future demand and thereby identify where and when parts of the RAN can be temporarily shut down, maintaining the bare-minimum network coverage and reducing energy consumption in the process by 25% without adversely impacting on perceived network performance.
Turkcell, for example, determined that AI was able to reduce network energy consumption by ~63GWh – to put that into context, it’s equivalent to the energy required to train OpenAI’s GPT-4.
Challenges
Applying AI to the operations of the network is not without its challenges.
Insufficient data is one of the biggest constraints, often because passive infrastructure such as diesel generators, rectifiers and AC, and even some network equipment, are not IP-connected to allow access to system logs and external control. Alternatively, there may not be enough data to model all eventualities, or some of the data may remain too privacy sensitive even when anonymised – synthesising data using AI to fill these gaps is one potential solution.
Deploying the AI/ML models themselves also throws up a number of considerations.
Many AI systems are developed and deployed in isolation and hence may inadvertently work against one another; moving to multi-vendor AI-native networks within 6G may compound this issue.
The AI will also need to be explainable, opening up the AI/ML models’ black-box behaviour to make it more intelligible to humans. The Auric framework that AT&T use for automatically configuring basestations is based on decision trees that provide a good trade-off between accuracy and interpretability. Explainability will also be important in uncovering adversarial attacks, either on the model itself, or in attempts to pollute the data to gain some kind of commercial advantage.
Skillset is another issue. Whilst AI skills are transferable into the telecoms industry, system performance will be dependent on deep telco domain knowledge. Many MNOs are experimenting in-house, but it’s likely that AI will only realise its true potential through greater collaboration between the Telco and AI industries; a GSMA project bringing together the Alan Turing Institute and Telenor to improve Telenor’s energy efficiency being a good example.

Perhaps the biggest risk is that the ecosystem fails to become sufficiently open to accommodate 3rd party innovation. A shift to Open RAN principles combined with 6G standardisation, if truly AI-native, may ultimately address this issue and democratise access. Certainly there are a number of projects sponsored within the European Smart Networks and Services Joint Undertaking (SNS JU) such as ORIGAMI that have this open ecosystem goal in mind.
Takeaways
The global economy today is fuelled by knowledge and information, the digital ICT sector growing six times faster than the rest of the economy in the UK – AI will act as a further accelerant.
Achieving its full potential will be dependent on a paradigm shift away from just connecting things, to enabling “connected intelligence”. Future networks will need to get ‘smarter’, and will likely only achieve this by embracing AI throughout.
The UK is a leader in AI investment within Europe; but can it harness this competence to successfully deliver the networks of tomorrow?