
The future of AI compute is photonics… or is it?
Exploring the potential of photonics to improve compute efficiency
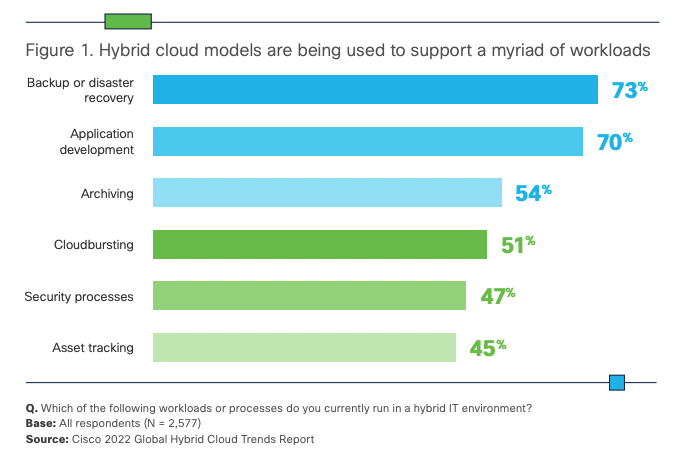
The computing landscape is one of constant change and the move to cloud has arguably been the most transformative in recent years. Early concerns around security have given way to adoption – according to Cisco’s (2022), 82% of businesses now routinely use hybrid cloud. Ironically they found it’s often security concerns driving a hybrid-cloud approach by giving teams the ability to selectively place workloads in public clouds while keeping others on-prem, or using different regions to meet data residency requirements.
But with players such as AWS, GCP and Azure creating a stranglehold on the market, there is growing awareness and a movement away from becoming too dependent on any single Cloud Service Provider (CSP), instead taking a multi-cloud approach.
Decentralisation is currently du jour in many aspects of the online world, most notably in finance (DeFi), and is starting to gain attention in the compute space through companies such as StorJ, Akash and Threefold – in essence, a blockchain-enabled approach that harnesses distributed compute & storage and will no doubt contribute to the Web3 scaffolding that underpins the future metaverse.
But decentralisation is a radical approach, and only suited to particular applications. For most enterprises today, the focus is on successfully migrating their apps into the cloud, and employing services from multiple CSPs to mitigate the dangers of becoming overly reliant on any single provider. But as many are discovering, taking a multi-cloud approach brings its own complications.
This article looks at some of the considerations and challenges that enterprises face when migrating to multi-cloud, and the resources that are out there to help them.
Cloud exuberance is over
Much has been said regarding the benefits of migrating enterprise apps to the cloud: more agility and flexibility in gaining access to resources as and when needed; an ability to scale rapidly in accordance with business needs; enabling apps hosted on-prem to burst into the cloud to accelerate workload completion time and/or generate insights with more depth and accuracy.
But it’s not all plain sailing, the hype surrounding the cloud often hides a number of drawbacks that have resulted in many businesses failing to realise the benefits expected – a recent study by Accenture Research found that only one in three companies reported achieving their cloud aims.
“Lift and shift” of legacy apps to the cloud doesn’t always work due to issues around data gravity, sovereignty, compliance, cost, and interdependencies; or perhaps because the app itself has been optimised to a specific hardware and OS used on-prem that isn’t readily available at scale in the cloud. This problem is further exacerbated by enterprises needing to move to a multi-cloud architecture.
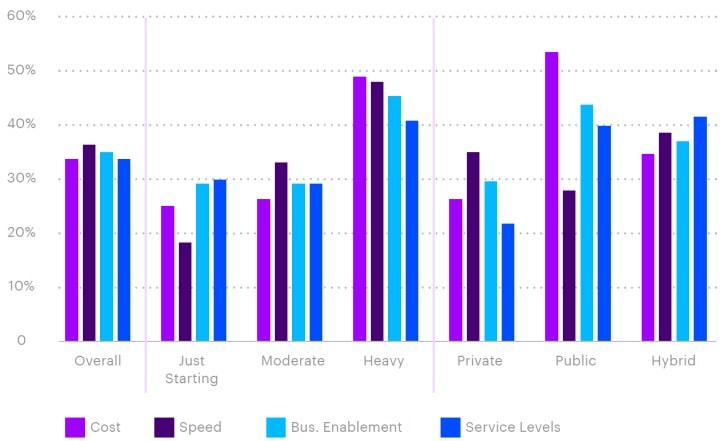
Many believe that utilising cloud resources has a lower total cost of ownership than operating on-prem. But this doesn’t always materialise and depends on the type of systems, apps and workloads that are being considered for migration.
In the case of high performance compute (HPC) which is increasing in importance for deep learning models, simulations and complex business decisioning, enterprises running these tasks on their own infrastructure commonly dimension for high utilisation (70-90%) whereas pricing in the cloud is often orientated towards SaaS-based apps where hardware utilisation is typically <20%.
For many enterprises therefore, embarking on a programme of modernisation often results in getting caught in the middle, struggling to reach their transformation goals amidst a complex dual operating environment with some systems migrated to the cloud whilst others by necessity stay on-prem.
Optimising workloads for the cloud
For those workloads that are migrated to the cloud, delivering on the cost & performance targets set by the enterprise will be dependent on real-time analysis of workload snapshots, careful selection of the most appropriate instance types, and optimisation of the workloads to the instances that are ultimately used.
Achieving this requires a comprehensive understanding of all the compute resources available across the CSPs (assuming a multi-cloud approach), being able to select the best resource type(s) and number of instances for a given workload and SLA requirements (resilience, time, budget). In addition, where spot/pre-emptible instances are leveraged, workload data needs to be replicated between the CSPs and locations hosting the spot instances to ensure availability.
Once the target instance types are known, workload performance can be tuned using tools such as Granulate that optimise OS-level scheduling and resource management to improve performance (up to 40-60%), especially for those instances leveraging new silicon.

Similarly, companies such as CloudFix help enterprises ensure their AWS instances are auto-updated with the latest patches to deliver a more compliant cloud that performs better and costs less by removing the effort of applying manual fixes.
Spot instances offered by the CSPs at a discount are ideal for loosely coupled HPC workloads, and often instrumental in helping enterprises hit their targets on performance and cost; but navigating the vast array of instance types and pricing models is far from trivial.
Moreover, prices often fluctuate based on demand, availability, and region. 451 Research’s Cloud Price Index (CPI) for instance recorded more than 1.2 million service changes in 2021 (SKUs added, SKUs removed, price increases and price decreases).
So whilst spot instances can help with budgetary targets and economic viability for HPC workloads, juggling instances to optimise cost and break-even point between reserved instances, on-demand, and spot/preemptible instances, versus retaining workloads on-prem, can become a real challenge for teams to manage.
Furthermore, with spot prices fluctuating frequently and resources being reclaimed with little notice by the CSP, teams need to closely monitor cloud usage, throttling down workloads when pricing rises above budget, migrating workloads when resources are reclaimed, and tearing down resources when they’re no longer needed. This can soon become an operational and administrative nightmare.
Cloud Management Platforms
Cloud Management Platforms (CMP) aim to address this with a set of tools for streamlining operations and enabling cloud resources to be utilised more effectively.
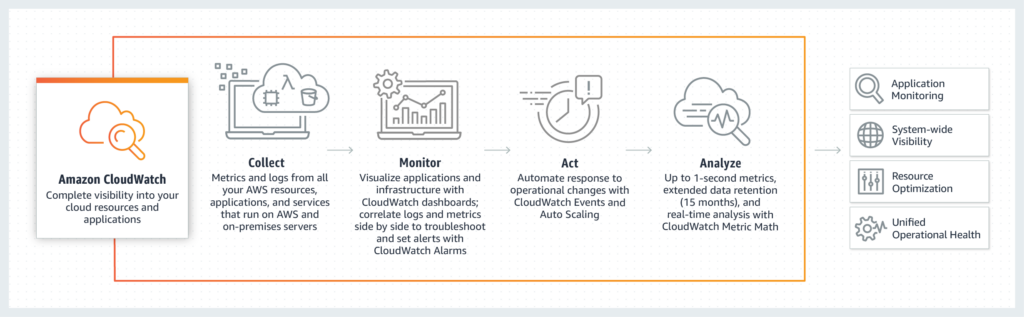
Whilst it’s true that CSPs provide such tools to aid their customers (such as AWS CloudWatch), they are proprietary in nature and vary in functionality, complicating the situation for any enterprise with multi-cloud deployments – in fact, Cisco found that a third of responding organisations highlighted operational complexity as a significant concern when adopting hybrid or multi-cloud models.
This is where CMPs come in, providing a “unified” experience and smoothing out the differences when working with multiple CSPs.
Such platforms provide an ability to:
CMPs achieve this by leveraging the disparate resources and tooling of the respective cloud providers to deliver a single homogenised set of resources for use by the enterprise’s apps.
Moreover, by unifying all elements of provisioning, scheduling and cost management within a single platform, they enable a more collaborative working relationship between teams within the organisation (FinOps). FinOps has demonstrated a reduction in cloud spend by 20-30% by empowering individual teams to manage their cloud usage whilst enabling better alignment with business metrics and strategic decision-making.
Introducing YellowDog
YellowDog is a leader in the CMP space with a focus on enterprises seeking a mix of public, private and on-prem resources for HPC workloads.
In short, the YellowDog platform combines intelligent orchestration, scheduling and dynamic policy-driven provisioning at scale across on-prem, hybrid and multi-cloud environments using agent technology. The platform has applicability ranging from containerised workloads through to supporting bare-metal servers without a hypervisor.
Compute resources are formulated into “on-demand” clusters and abstracted through the notion of workers (threads on instances). YellowDog’s Workload Manager is a cloud native scheduler that scales beyond existing technologies to millions of processor cores, working across all the CSPs, multi-region, multi-datacentre and multi-instance shapes.
It can utilise Spot type instances where others can’t, acting as both a native scheduler and meta-scheduler (invoking 3rd party technologies and creating specific workload environments such as Slurm, OpenMPI etc.) to work with both loosely coupled and tightly coupled workloads.
YellowDog’s workload manager matches workload demand with the supply of workers whilst ensuring compatibility (via YellowDog’s extensive Image Registry) and automatically reassigning workloads in case of instance removal – effectively it is “self-healing”, automatically provisioning and deprovisioning instances to match the workload queue(s).
The choice of which workers to choose is managed by the enterprise through a set of compute templates defining workload specific compute requirements, data compliance restrictions and enterprise policy on use of renewables etc. Compute templates can also be attribute-driven via live CSP information (price, performance, geographic region, reliability, carbon footprint etc.), and potentially in future with input from CPU and GPU vendors (e.g., to help optimise workloads to new silicon).
On completion, workload output can be captured in YellowDog’s Object Store Service for subsequent analysis and collection or as input to other workloads. By combining multiple storage providers (e.g. Azure Blob, Amazon S3, Google Cloud Storage) into one coherent data surface, YellowDog mitigate the issue of data gravity and ensure that data is in the right place for use within a workload. YellowDog also supports the use of other file storage technologies (e.g. NFS, Lustre, BeeGFS) for data seeding and management.
In addition, the enterprise can define pipelines that are automatically triggered when a new file is uploaded into an object store that spin up instances and work on the new file, and then shut down when the work is completed.
As jobs are running, YellowDog enables different teams to monitor their individual workloads with real-time feedback on progress and status, as well as providing an aggregate view and ability to centrally manage quotas or allowances for different clouds, users, groups and so forth.
In summary
Multi-cloud is becoming the norm, with businesses typically using >2 different providers. In fact Cisco found that 58% of those surveyed use 2-3 CSPs for their workloads, with 31% using more than 4. Effective management of these multi-cloud environments will be paramount to ensuring future enterprise growth. Cloud Management Platforms, such as that offered by YellowDog, will play an important role in helping enterprises to maximise their use of hybrid / multi-cloud.
Exploring the potential of photonics to improve compute efficiency
Exploring more esoteric approaches to the future of compute

