
The future of AI compute is photonics… or is it?
Exploring the potential of photonics to improve compute efficiency
The focus of AI and ML innovation to-date has understandably been in those areas characterised by an abundance of labelled data with the goal of deriving insights, making recommendations and automating processes.
But not every potential application of AI produces enough labelled data to utilise such techniques – use cases such as spotting manufacturing defects on a production line is a good example where images of defects (for training purposes) are scarce and hence a different approach is needed.
Interest is now turning within academia and AI labs to the harder class of problems in which data is limited or more variable in nature, requiring a different approach. Techniques include: leveraging datasets in a similar domain (few-shot learning), auto-generating labels (semi-supervised learning), leveraging the underlying structure of data (self-supervised learning), or even synthesising data to simulate missing data (data augmentation).
Characterising limited-data problems
Deep learning using neural networks has become increasingly adept at performing tasks such as image classification and natural language processing (NLP), and seen widespread adoption across many industries and diverse sectors.
Machine Learning is a data driven approach, with deep learning models requiring thousands of labelled images to build predictive models that are more accurate and robust. And whilst it’s generally true that more data is better, it can take much more data to deliver relatively marginal improvements in performance.

Figure 1: Diminishing returns of two example AI algorithms [Source: https://medium.com/@charlesbrun]
Manually gathering and labelling data to train ML models is expensive and time consuming. To address this, the commercial world has built large sets of labelled data, often through crowd-sourcing and through specialists like iMerit offering data labelling and annotation services.
But such data libraries and collection techniques are best suited to generalist image classification. For manufacturing, and in particular spotting defects on a production line, the 10,000+ images required per defect to achieve sufficient performance is unlikely to exist, the typical manufacturing defect rate being less than 1%. This is a good example of a ‘limited-data’ problem, and in such circumstances ML models tend to overfit (over optimise) to the sparse training data, hence struggle to generalise to new (unknown) images and end up delivering poor overall performance as a result.
So what can be done for limited-data use cases?
A number of different techniques can be used for addressing these limited-data problems depending on the circumstances, type of data and the amount of training examples available.
Few-shot learning is a set of techniques that can be used in situations where there are only a few example images (shots) in the training data for each class of image (e.g. dogs, cats). The fewer the examples, the greater the risk of the model overfitting (leading to poor performance) or adversely introducing bias into the model’s predictions. To address this issue, few-shot learning leverages a separate but related larger dataset to (pre)train the target model.
Three of the more popular approaches are meta-learning (training a meta-learner to extract generalisable knowledge), transfer learning (utilising shared knowledge between source and target domains) and metric learning (classifying an unseen sample based on its similarity to labelled samples).
Once a human has seen one or two pictures of a new animal species, they’re pretty good at recognising that animal species in other images – this is a good example of meta-learning. When meta-learning is applied in the context of ML, the model consecutively learns how to solve lots of different tasks, and in doing so becomes better at learning how to handle new tasks; in essence, ‘learning how to learn’ similar to a human – illustrated below:
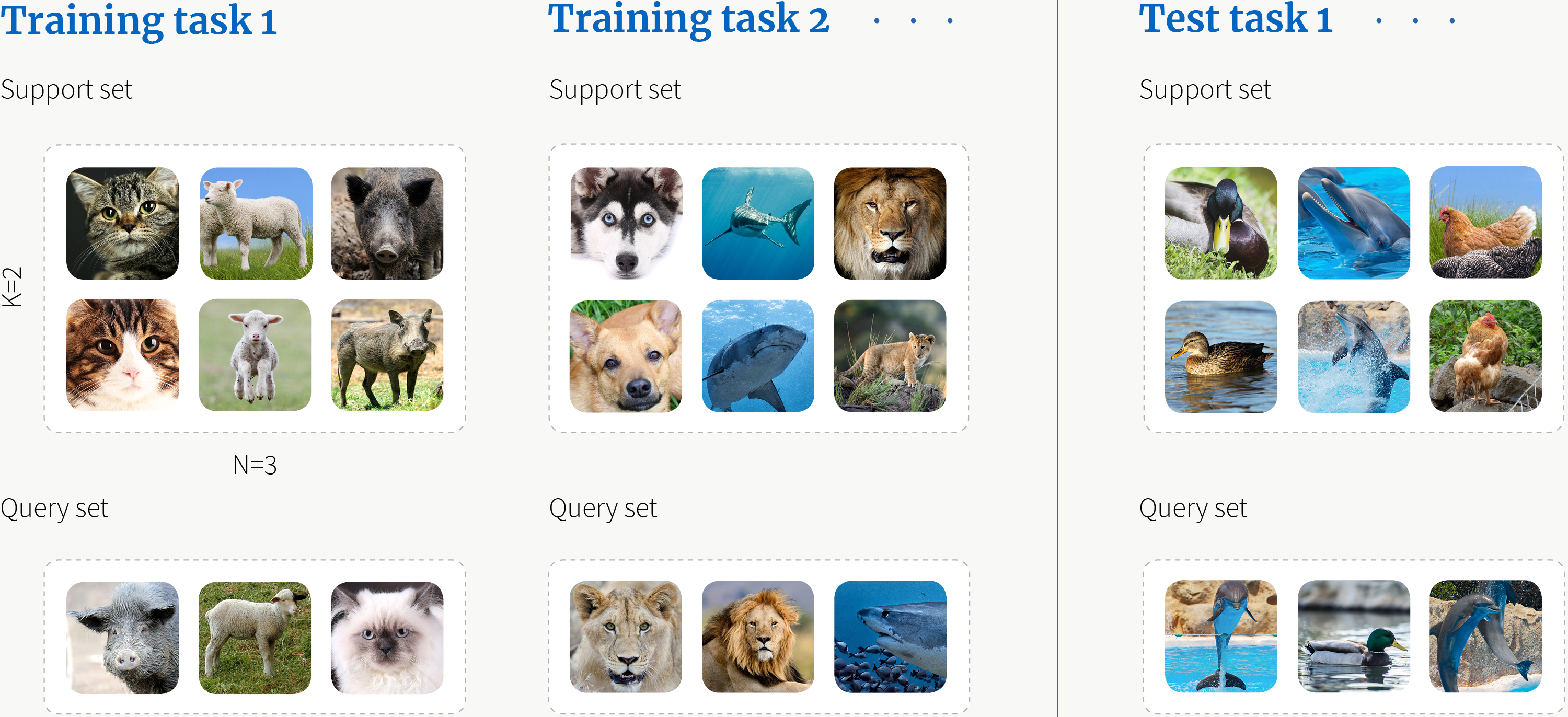
Figure 2: Meta-learning [Source: www.borealisai.com]
Transfer learning takes a different approach. When training ML models, part of the training effort involves learning how to extract features from the data; this feature extraction part of the neural network will be very similar for problems in similar domains, such as recognising different animal species, and hence can be used in instances where there is limited data.
Metric learning (or distance metric learning) determines similarity between images based on a distance metric and decides whether two images are sufficiently similar to be considered the same. Deep metric learning takes the approach one step further by using neural networks to automatically learn discriminative features from the images and compute the distance metric based on these features – very similar in fact to how a human learns to differentiate animal species.
Techniques such as few-shot learning can work well in situations where there is a larger labelled dataset (or pre-trained model) in a similar domain, but this won’t always be the case.
Semi-supervised learning can address this lack of sufficient data by leveraging the data that is labelled to predict labels for the rest hence creating a larger labelled dataset for use in training. But what if there isn’t any labelled data? In such circumstances, self-supervised learning is an emerging technique that sidesteps the lack of labelled data by obtaining supervisory signals from the data itself, such as the underlying structure in the data.
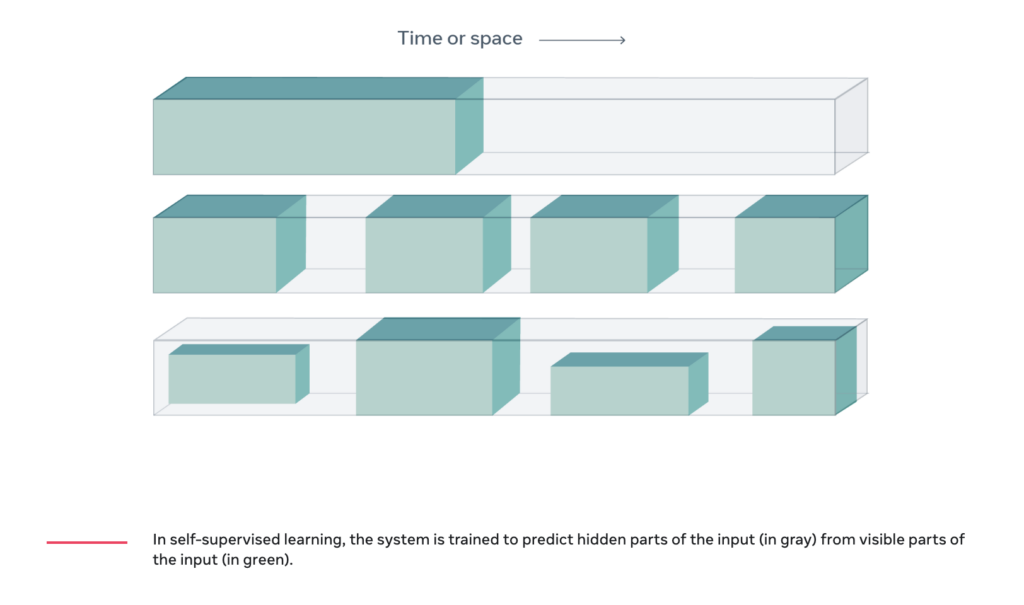
Figure 3 Predicting hidden parts of the input (in grey) from visible parts (in green) using self-supervised learning [source: metaAI]
An alternate approach is simply to fill the gap through data augmentation by simulating real-world events and synthesising data samples to create a sufficiently large dataset for training. Such an approach has been used by Tesla to complement the billions of real-world images captured via its fleet of autonomous vehicles for training their AI algorithms, and by Amazon within their Amazon’s Go stores for determining which products each customer is taking from the shelves.

Figure 4: An Amazon Go store [Source: https://www.aboutamazon.com/what-we-do]
Whilst synthetic data might seem like a panacea for any limited-data problem, it’s too costly to simulate for every eventuality, and it’s impractical to predict anomalies or defects a system may face when put into operation.
Data augmentation has the potential to reinforce any biases that may be present in the limited amount of original labelled data, and/or causing overfitting of the model by creating too much similarity within the training samples such that the model struggles to generalise to the real-world.
Applying these techniques to computer vision
Mindtrace is utilising the unsupervised and few-shot learning techniques described previously to deliver a computer vision system that is especially adept in environments characterised by limited input data and where models need to adapt to changing real-life conditions.
Pre-trained models bringing knowledge from different domains create a base AI solution that is fine-tuned from limited (few-shot) or unlabelled data to deliver state-of-the-art performance for asset inspection and defect detection.
Figure 6: Mindtrace [Source: https://www.mindtrace.ai]
This approach enables efficient learning from limited data, drastically reducing the need for labelled data (by up to 90%) and the time / cost of model development (by a factor of 6x) whilst delivering high accuracy.
Furthermore, the approach is auto-adaptive, the models continuously learn and adapt after deployment without needing to be retrained, and are better able to react to changing circumstances in asset inspection or new cameras on a production line for detecting defects, for example.
The solution is also specifically designed for deployment at the edge by reducing the size of the model through pruning (optimal feature selection) and reducing the processing and memory overhead via quantisation (reducing the precision using lower bitwidths).
Furthermore, through a process of swarm learning, insights and learnings can be shared between edge devices without having to share the data itself or process the data centrally, hence enabling all devices to feed off one-another to improve performance and quickly learn to perform new tasks (Bloc invested in Mindtrace in 2021).
In summary
The focus of AI and ML innovation to-date has understandably been in areas characterised by an abundance of labelled data to derive insights, make recommendations or automate processes.
Increasingly though, interest is turning to the harder class of problems with data that is limited and dynamic in nature such as the asset inspection examples discussed. Within Industry 4.0, limited-data ML techniques can be used by autonomous robots to learn a new movement or manipulation action in a similar way to a human with minimal training, or to auto-navigate around a new or changing environment without needing to be re-programmed.
Limited-data ML is now being trialled across cyber threat intelligence, visual security (people and things), scene processing within military applications, medical imaging (e.g., to detect rare pathologies) and smart retail applications.
Mindtrace has developed a framework that can deliver across a multitude of corporate needs.

Figure 7: Example Autonomous Mobile Robots from Panasonic [Source: Panasonic]
Exploring the potential of photonics to improve compute efficiency
Exploring more esoteric approaches to the future of compute

