
The future of AI compute is photonics… or is it?
Exploring the potential of photonics to improve compute efficiency
Once the stalwart of particle physicists, Formula 1 designers, and climate forecasters, the demand for HPC is rapidly going mainstream as corporates increasingly introduce deep learning models, simulations and complex business decisioning into their daily operations.
HPC can play a pivotal role in accelerating product design, tackling complex problems and enabling businesses to generate insights faster and with more depth and accuracy, and has applicability across an ever-widening range of industries including financial services, media, gaming and retail.
To-date, the only option for corporates seeking to access this level of compute was to build, maintain and operate dedicated HPC facilities in-house, but this brings a number of challenges. The first is cost – HPC systems are expensive, and only around 7% of the budget actually goes toward the hardware, the rest being consumed by buildings, staffing, power, cooling, networking etc. Moreover, because many of these systems are designed to support peak demand, utilisation can be as little as 60% for the majority of the time.
What’s more, significant additional capital is needed on a three year upgrade cycle to keep pace with demand as the business grows and the volume and complexity of workloads increases, and/or to reap the benefits of the latest computing technology. But this computing resource is intrinsically finite and hence projects within an organisation need to be prioritised leading to many missing out or having to step aside if more urgent tasks come along.
HPC on-premise deployments are traditionally designed and optimised around particular use cases (such as climate forecasting) whereas corporates today need HPC resources that can support a much broader set of applications and be able to adapt as workload characteristics evolve in reaction to the fast-moving competitive landscape.
Many companies are therefore turning to cloud-based HPC.
[Image Source: www.seekpng.com]
First and foremost, cloud HPC provides more flexibility for an organisation to gain access to HPC resources as and when needed and scale to match individual workload demands.
It also opens up more choices for the corporate; for instance, employing 10x HPC resources to accelerate product design and gain competitive advantage by being first to market. Or increasing productivity by removing compute barriers so that the corporate can use more detailed simulations or eliminate the effort in simplifying deep learning models to fit inside legacy hardware.
A cloud-based approach mitigates the risk in cost & complexity of operating HPC on-prem by providing flexibility to manage the cost/performance trade-off, allowing HPC environments to be created on the fly and then torn down as soon as the workloads have completed to avoid the corporate paying for resources and software licenses that are no longer needed.
To accommodate this variability in customer demand, CSPs dimension their cloud infrastructure with excess capacity which is powered-up and ready to use but otherwise sitting idle. To offset the monetary and environmental impact of this idle infrastructure, CSPs offer this excess capacity in the form of preemptible instances at massive discounts (up to 90% in some cases) but with the caveat that the resource can be reclaimed by the CSP at a moment’s notice if required by a full-paying customer – a corporate choosing to use these preemptible instances is essentially trading availability guarantees for a variable but much reduced ‘Spot’ price.
HPC workloads such as running a simulation, training a deep learning model, analysing a big data set or encoding video are periodic and batch in nature and not dependent on continuous availability hence a good fit for preemptible resources. If some of the resource instances within the HPC cluster are reclaimed during processing, the workload slows but does not completely stop. Ideally though, it should be possible to quickly and seamlessly re-distribute the part of the workload that was interrupted to alternate resources at the same or a different CSP thereby ensuring that the workload still completes on time – this is possible but not easy, and an area of speciality for some 3rd party tool providers.
With the increase in availability of HPC resources twinned with the ability to closely manage cost, corporates get the opportunity to open up HPC resources to the wider organisation, enabling a wider range of teams, departments and geographically dispersed business units to access the processing power they need whilst being able to track cost and performance and focus on outcomes rather than managing operational complexity.
In a world that is speeding up, becoming more competitive, and being driven by continuous integration and continuous delivery (CI/CD), easy access to cost-effective HPC resources on-the-fly is likely to become a key requirement for any corporate wishing to stay ahead.
Running complex technical workloads in the cloud is not as simple as swiping a credit card and getting a cloud account.
Many of the companies coming to cloud HPC will be specialists in their area, and may also have cloud expertise, but will need support in composing their workloads to take advantage of the parallelism within the cloud HPC stack, and tools to help them optimise their use of cloud resources.
Such tools will need to work across both workload management and resource provisioning, balancing them to meet the corporate’s target SLAs whether that be dynamically adding more resource to complete a workload on time, or prioritising and scheduling workloads to make most effective use of resources to meet budgetary constraints.
More specifically, tools will be needed that can:
Conduct realtime analysis of workload snapshots to determine their compute requirements.
Sift through the bewildering array of 30,000 different compute resources offered by the CSPs to ensure the best fit for each individual workload whilst also abiding by any corporate policy or individual budgetary targets. Factors that may need to be taken into account when selecting appropriate resources include:

Create clusters of mixed instance types, and do this x-CSP to avoid vendor lock-in and/or to circumvent constraints imposed by any single CSP when dealing with large clusters.
Ensure the workload data is available in the relevant cloud by replicating data between CSPs and locations to ensure availability should a workload need to be executed there.
Monitor when workloads start and complete to ensure that resources are not left running when no workloads are executing.
Intelligently monitor spot/preemptible instances (where used) to ensure that workload cost stays within budget as the spot pricing fluctuates with demand, and reallocate workloads seamlessly if instances are reclaimed by the CSP to ensure that the composite cluster is able to deliver against the workload targets.
Integrate into a corporate’s DevOps and CI/CD processes to enable accessibility of HPC resources more broadly across the organisation.
Provide a single view of workload status and enable users to dynamically make changes to their workloads to deliver results on time and within their project budgetary constraints.
Coordinate with any 3rd party schedulers already used by the corporate (e.g., Slurm, IBM LSF, TIBCO DataSynapse GridServer etc.) to provide a single meta system for workload submission and management across on-prem, fixed cloud and public cloud HPC resources.
The relative importance of these different tools and requirements will very much be determined by the type of company seeking to utilise cloud HPC, the level of resources they may already have in place and the type of workloads they need to support.
Three example client types are outlined:
HPC stalwarts
Multi-national organisations and specialist corporates in sectors such as academia, engineering, life sciences, oil & gas, aircraft and automotive that already have an HPC data centre on-prem but aim to supplement it with cloud HPC resources to avoid the cost of building out and maintaining additional HPC resources themselves to increase capacity.
Such clients may use cloud resources as an extension of their existing HPC for use with all workloads, or segment and only use cloud for adhoc non-critical (and loosely coupled workloads), or perhaps just for ‘bursting’ into the cloud to deal with peaks in demand either because the planned workload exceeded expectations and bursting was needed to complete it on time (e.g., CGI rendering), or bursting was employed to speed-up execution and produce simulation results more quickly. By using the cloud as an adjunct enables these companies to extend the usefulness of their existing on-prem systems, and any new systems they deploy can be designed with less peak performance capacity by being able to burst into the cloud whenever needed.
Given that the corporate will already have on-prem and/or private cloud infrastructure, cloud HPC tools will be needed that can interface with the existing 3rd party workload schedulers. Equally, any cloud HPC resources that are employed may need to be matched to the on-prem resource types already in-use, hence intelligent tooling will be needed that can analyse individual workload requirements and provision the most appropriate cloud resources across the myriad of available instance options from the CSPs, and map the workload accordingly across the on-prem and cloud infrastructure.
Depending on the workload, the corporate may also decide to use spot/preemptible instances to complete batch processing tasks without loading other cloud resources and/or as a way of managing cost.
Cloud-native corporates
Corporates in sectors such as financial services, retail, media, gaming, manufacturing and logistics that are dependent on high-performance compute to drive their deep learning models, simulations and business decisioning to maintain a competitive edge but with insufficient funds and/or interest in deploying and managing dedicated HPC resources on-prem hence reliant on such resources being provided via the cloud.
Given the mission-critical nature of their workloads, such corporates are likely to follow a multi-cloud strategy to provide resiliency and de-risk dependency on a single provider. Selection of resources may also be driven by corporate sustainability goals, with a preference for CSPs and/or specific CSP data centres that maximise use of renewables.
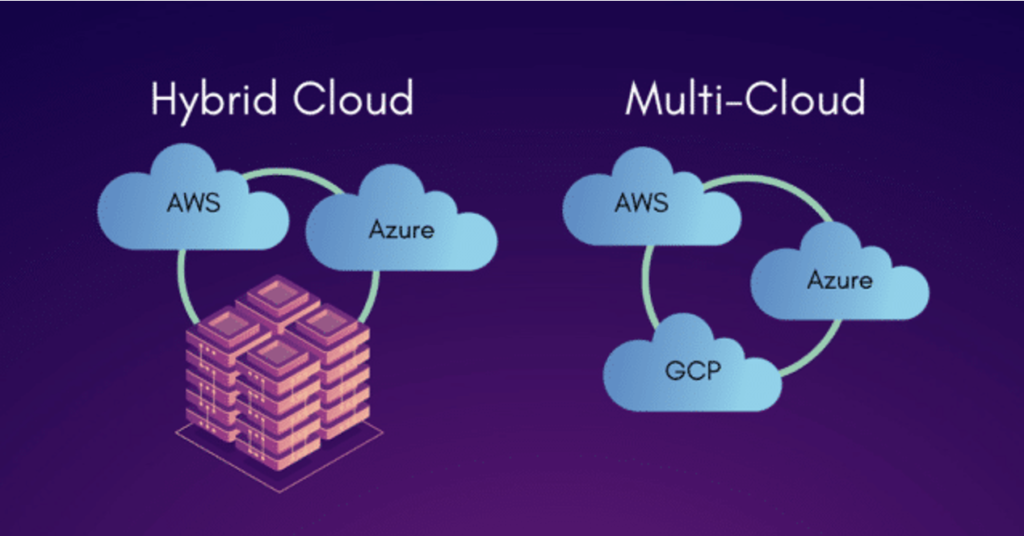
Intelligent tooling will also be needed for use by the corporate in parallelising their workloads and integrating into their existing DevOps processes, and a dashboard providing oversight of HPC resources employed and workload status.
Startups/scale-ups
Similar to the cloud-native corporates, many startups/scale-ups utilising deep learning for NLP, computer vision etc. are keen on gaining access to HPC resources to accelerate their product development and time to market, and/or would like to develop products and services that can scale up and down in the cloud, but may not have the budget or expertise to achieve this.
Such companies are therefore wholly dependent on automated tools that enable them to programmatically control their usage via DevOps interfaces and dynamically switch between different CSPs and instances to minimise their costs. Primary usage will be via preemptible resources, and startups may also choose to use older generation instances to meet budgetary constraints.
YellowDog is a pioneer in the cloud HPC space, providing solutions that enable intelligent orchestration, scheduling and provisioning at scale across on-prem, hybrid and multi-cloud environments and delivering on all the requirements outlined above.
In addition to providing benefits to companies already employing HPC, they’re unique in being able to generate clusters delivering HPC levels of compute using spot/preemptible instances hence are well placed to support the new breed of companies needing access to HPC performance levels at an affordable price and to provide startups with a base platform that enables them to easily develop a new autoscaling product or service hence reducing their time to market and simplifying development.
A particular speciality of YellowDog is the ability to rapidly spin-up massive scale HPC clusters that aggregate resources from multiple CSPs and/or across multiple regions to circumvent the scaling limits in any particular CSP; in 2021, YellowDog successfully demonstrated creation of a cluster utilising 3.2million vCPUs on AWS to run an HPC workload with 95% utilisation, and achieved this feat in under an hour.
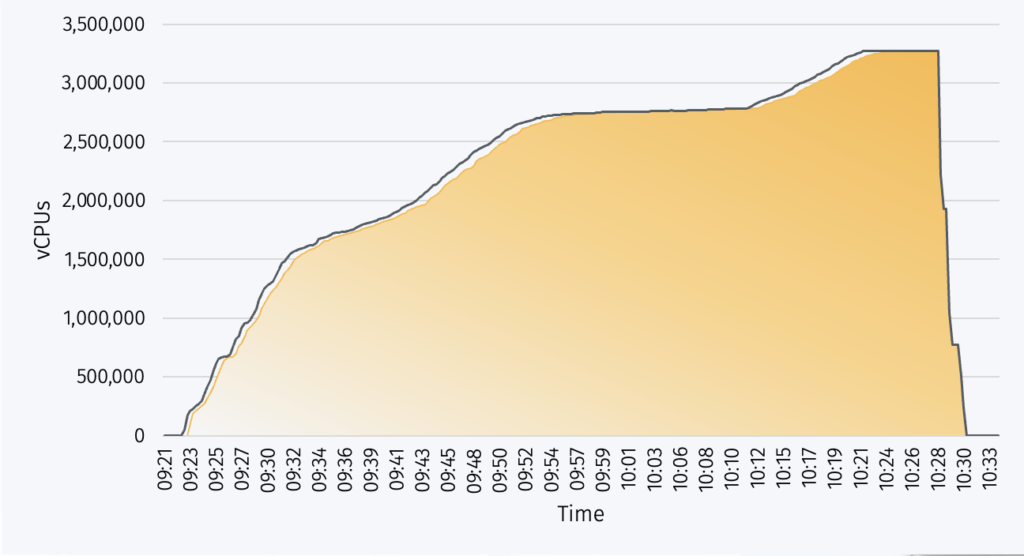
Figure 4 Scale-up to 3.2 million vCPUs and rapid scale-down on job completion (YellowDog; AWS)
The YellowDog platform provides a straightforward GUI enabling engineers and scientists to use the platform without needing to be HPC specialists, and also provides a sophisticated dashboard and API access for managing workloads and provisioning preferences, including an ML-based prediction of completion time thereby enabling customers to easily flex the resources being employed to meet a particular deadline or budgetary constraint.
Unique in the market, YellowDog also compiles a realtime insight on the myriad of different instances offered by the main CSPs[1] with regard to their machine performance, pricing, and use of renewables, and utilises this intelligence within the YellowDog platform to deliver optimal provisioning for its clients.
Whilst there are other companies offering solutions to help clients with their cloud orchestration and management, only YellowDog provide orchestration twinned with intelligent scheduling and provisioning at sufficient scale to deliver compute capabilities at HPC performance levels, and at a price point using spot/preemptible resources that meets the growing industry demand, and via a platform and set of tools that enable all to enjoy the benefits of cloud HPC.
The world is speeding up.
Easy access to HPC levels of compute via the cloud is changing the economics of product development, increasing the pace of innovation and enabling corporates to increase agility, accuracy, and critical insights in today’s data-driven economy. By harnessing preemptible instances and spot pricing, even the smallest of companies and startups can now afford to run HPC workloads.
Preemptible instances ensure that cloud resources do not lie idle, and bring environmental benefits as well as incremental revenues for the CSPs and lower costs for companies utilising the cloud – a veritable win:win for all, and demonstrates that HPC systems in the cloud can be cost-comparable to on-prem alternatives whilst bringing many advantages.
Harnessing the potential of cloud HPC whilst meeting all other business objectives though is no mean feat and will be dependent on intelligent tooling. YellowDog is a pioneer in this space and a perfect partner for any business looking to leverage cloud HPC resources to gain a competitive edge.
[1] Amazon Web Services (AWS), Google Cloud Platform, Microsoft Azure, Oracle Cloud Infrastructure and Alibaba
Exploring the potential of photonics to improve compute efficiency
Exploring more esoteric approaches to the future of compute

